- 产品与解决方案
- 行业解决方案
- 服务
- 支持
- 合作伙伴
- 关于我们





人工智能时代,百行百业纷纷拥抱大模型,然而应用大模型和数智化转型,不仅要聚焦算力,还需兼顾存储、网络、训练、适配等多个环节,否则就会形成木桶原理下的短板效应,影响整体性能。其中,存储作为与数据要素高度相关的核心基础设施,决定了调取、开发、训练、推理的效率。因此,要用好大模型,这块“板”不能短。
如何打造面向大模型的基础设施?如何构建更先进的智算底座?作为高端GPU芯片及解决方案提供商,瀚博半导体(上海)有限公司(下称“瀚博半导体”)携手紫光股份旗下新华三集团,引入新华三分布式存储解决方案,打造面向大模型训推的智算中心,以应对数智时代下百模千态的发展需求。
大模型训推面临“木桶理论”
存储需求再升级
瀚博半导体致力于“为数字和像素世界提供浩瀚算力”,目前拥有两代GPU芯片系列,并衍生AI、渲染、视频三大产品线,助力大模型与生成式人工智能、智算数据中心、智慧工业、车路协同等应用场景落地。
面向推理训练场景的蓬勃需求,瀚博半导体推出VGX VA16大模型训推一体机,显存容量达到2T,算力达到2.3PFLOPS,可支持四千亿以上参数大模型,在业内具有独特优势。但在智算中心大规模部署的过程中,瀚博半导体面临着存储环节带来的全方位挑战:
一方面,大模型预训练过程需要调用海量数据,但传统存储模式导入时间慢,造成数据准备时间过长,而且会产生互相干扰抢资源的现象;另一方面,如果读写加载速度跟不上训练速度,会造成GPU“等待”,形成极大资源浪费,也影响模型分发部署的效率。因此,面向大模型的算力基础设施,要同时满足海量数据、高带宽、高IOPS、高并发等需求,实现高效数据管理,减少数据在存储间的搬迁过程,分布式存储成为大模型时代下的“最优解”。
瀚博半导体携手新华三
分布式存储完美满足智算需求
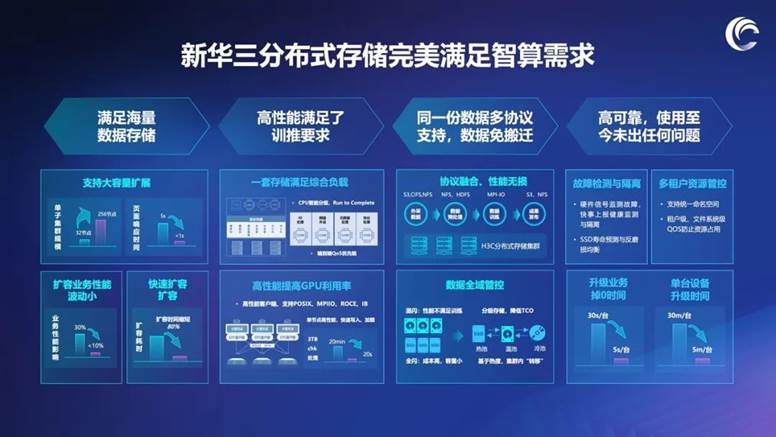
针对瀚博半导体建设智算中心、聚焦大模型训推场景的实际需要,新华三集团为其量身定制分布式存储解决方案,带来海量易扩容、高性能存储、多协议支持、高可靠安全四大提升,全方位满足智算业务场景的多重需求。
海量易扩容:在大容量的基础上进一步支持平滑扩展,并且大幅降低了扩容过程对业务性能的影响,相比传统方案扩容时间缩短80%,能够满足企业灵活发展的需求。
高性能存储:一套存储即可满足训推过程中的综合负载,凭借单节点超高性能,实现快速写入和加载,高速数据迁移,减少“等待”时间,显著提高GPU利用率。
多协议支持:在同一存储池中支持POSIX、NFS、S3、HDFS等不同协议以及互通,实现性能无损,满足不同项目对文件、对象、大数据的复杂全域管控需求。
高可靠安全:在合作过程中,新华三分布式存储产品保持了0故障记录,即使千卡集群发生故障,在领先的故障检测与隔离能力的支持下,仅5秒即可恢复训练。
在分布式存储之外,瀚博半导体还与新华三集团就服务器、智算、云桌面等领域展开合作,推进互认互配,共同研发解决方案,并且携手与产业上下游建立生态协同能力,与操作系统、硬件厂商、高校研究所、行业伙伴进行优势互补,构建更符合大模型时代需求的产业生态。
面向AI发展催生的存储需求变革,近期,新华三集团更发布了下一代AI数据存储平台H3C UniStor Polaris X20000系列,助力产业进一步打破“存力瓶颈”,补齐发展大模型的“短板”。未来,新华三将继续秉持“精耕务实,为时代赋智慧”的理念,提供“云-网-安-算-存-端”全栈技术能力,携手伙伴为百行百业构筑AGI时代智算基石,加速智能化时代的全面到来。









