


 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友MFR和MP技术
文/吴爱慧 李宜清
1 MFR技术
1.1 MFR简介
MFR多链路帧中继(Multilink Frame Relay)是为帧中继用户提供的一种性价比比较高的带宽解决方案。将多个低速的物理接口捆绑在一起,提供给用户使用,从而达到用户对带宽比较高的需求,同时又不会增加多少网络设备投资。多链路帧中继特性提供一种逻辑接口:MFR接口,由多个帧中继物理链路捆绑而成,从而可以在帧中继网络上提供高速率、大带宽的链路(在逻辑上可以看作是一条FR的链路)。配置MFR接口时,为使捆绑后的接口带宽最大,建议对同一个MFR接口捆绑速率一致的物理接口,以减少管理开销。如图1所示,就是将4条E1/T1捆绑使用的示意图。

图1 MFR物理捆绑
1.2 Bundle和Bundle link
捆绑(bundle)和捆绑链路(bundle link)是多链路帧中继的两个基本概念。
一个MFR接口对应一个捆绑,一个捆绑中可以包含多个捆绑链路,一个捆绑链路对应着一个物理接口。捆绑对它的捆绑链路进行管理。二者的关系如图2 所示。
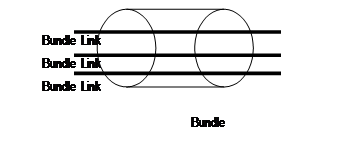
图2 Bundle和Bundle link
对于实际的物理层可见的是捆绑链路;对于实际的数据链路层可见的是捆绑。
1.3 MFR接口和物理接口
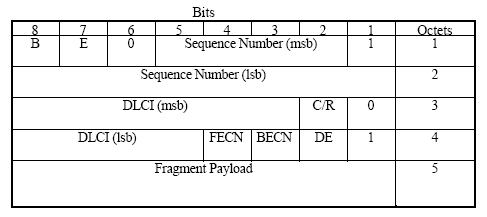
图3 MFR帧格式
B:表示Begin 开始标志,表示MFR分片的开始;
E:表示End 结束标志,表示是MFR分片的最后一片;
第6位:为0表示是MFR数据,为1时表示MFR的控制信息;
Sequence Number:表示MFR分片的序列号。
MFR接口是逻辑接口,多个物理接口可以捆绑成一个MFR接口。一个MFR接口对应一个捆绑,一个物理接口对应一个捆绑链路。对捆绑和捆绑链路的配置实际就是对MFR接口和物理接口的配置。
MFR接口的功能和配置与普通意义上的FR接口相同,也支持DTE、DCE接口类型,并支持QoS队列机制。当物理接口捆绑进MFR接口后,原来配置的网络层和帧中继链路层参数将不再起作用,而是使用此MFR接口的参数。
H3C实现的MFR基于帧中继论坛FRF.16 UNI/NNI MFR 协议(最新FRF16.1),为帧中继业务提供一个虚拟的物理接口MFR接口,该接口实际上是由多个真正的物理接口汇聚而成。MFR接口在协议中被称为Bundle捆绑,而组成该接口的多个物理接口则被称为Bundle Link。捆绑链路MFR接口为上层帧中继提供的传输带宽几乎为它捆绑的多个物理接口带宽的总和。
2 MP技术
2.1 MP概述
MP是MultiLink PPP的缩写,是出于增加带宽的考虑,将多个PPP通道捆绑使用产生的。这多个PPP通道捆绑成一条PPP链路使用,从网络层来看就只是一个逻辑通道、一条PPP链路。这里的PPP通道,习惯上把它叫做MP通道,这里的逻辑通道(PPP链路),习惯上把它叫做MP链路(有时也叫做MP父通道或者MP bundle);Linux内核的实现中,区分了channel与interface,这里的channel是PPP内部的,它与底层相连,但对PPP的网络层而言是不可见的,PPP的网络层看到的是一个interface,一个interface下面可能挂有多个channel。总而言之,MP里面连接PPP上下两层是个一对多的结构,这个层次结构的理解是理解MP的一个关键。
最喜欢使用MP的要数ISDN了,ISDN BRI口(2B+D)是常用的一种连接广域网的一种方式,在这种方式中,人们习惯使用DCC来达到一种带宽动态使用的目的,当带宽的需求超过64K(1B的带宽),自然就想利用另外一个B的带宽,而MP恰好能够很好地满足这个需求。在这里,MP主要是增加带宽的作用,当然,除此之外,MP还有负载分担的作用,这里的负载分担是链路层的负载分担;负载分担从另外一个角度解释就有了备份的作用。上述这些作用与MP的分片是没有关系的,MP的分片有什么作用呢?它可以起到减小传输时延的作用,特别是在一些低速链路上。
总结上面的内容,我们可得到MP的作用主要有下面几个:
1、增加带宽,结合DDR,可以做到动态调整;
2、负载分担;
3、备份;
4、利用分片减小时延。
2.2 MP的建链与协商过程
PPP分LCP与NCP两层,MP的实现机制严格依赖于这个层次关系。MP中一对多的结构具体到这个地方就是:在多个MP通道上进行LCP协商,在一条MP链路上进行NCP协商。与MP相关的选项主要在LCP协商中,这些选项决定了该通道是否可以作为MP链路的一个通道使用,该通道是否能绑定到某条MP链路,如何选择该通道要绑定的某条MP链路。
2.2.1 MP通道的绑定方式及如何绑定
RFC1990中提到了绑定方式有下列四种:
1、No authentication, no discriminator
2、Discriminator, no authentication
3、No discriminator, authentication
4、Discriminator, authentication
实际上,这四种绑定方式就是端点描述符与验证用户名的四种组合。这样的绑定方式就决定了MP中验证要在MP通道上进行而不能跑到BUNDLE上来,这样就决定绑定这个动作是发生在验证之后(有验证的话)的。
由此可见将链路绑定到Mp-group接口只有一种方式,就是在接口下直接指定相应的Mp-group接口,即相当于RFC1990中的第一种实现方式。在虚拟模板接口下指定捆绑方式时,可以使用用户名、终端标识符或者两者同时使用。
H3C产品支持3种类型的捆绑:
- authentication:根据PPP的验证用户名进行MP捆绑。
- both:同时根据PPP的验证用户名和终端标识符进行MP捆绑。
- descriptor:根据PPP的终端标识符进行MP捆绑。
用户名是指PPP链路进行PAP或CHAP验证时所接收到的对端用户名;终端标识符是用来唯一标识一台设备的标志,是指进行LCP协商时所接收到的对端终端标识符。系统可以根据接口接收到的用户名或终端标识符来进行MP捆绑,以此来区分虚模板接口下的多个MP捆绑(对应多条MP链路)。
2.2.2 MP的链路建立过程
各MP通道首先进行LCP协商,LCP报UP后,有验证的话进行验证协商,验证通过后进入网络阶段PPP_PHASE_NETWORK(没有验证的话直接进入PPP_PHASE_NETWORK),此时开始根据相应的绑定方式寻找对应BUNDLE,BUNDLE找不到时,开始创建一个新的BUNDLE(对应MP链路或叫做MP父通道),然后在这个BUNDLE上进行IPCP协商,IPCP协商通过后,则MP链路便可以正式使用,在上面传送IP报文了;如果找到BUNDLE,则该通道绑定到这个BUNDLE。
2.2.3 MP验证
无论是VT接口还是MP-GROUP接口下都不支持验证,只能在物理接口下进行验证配置。
VT配置的验证命令只是在PPPoFR、PPPoE、PPPoA链路配置MP时验证才起作用。
在捆绑两个子通道时,可以仅仅在一个子通道上配置验证,另外一个子通道不用配置验证;也可以两个都进行验证配置。
2.3 MP中报文的发送与接收
2.3.1 LCP报文的发送与接收
MP中LCP报文的发送与接收都是在MP各通道上进行,MP各通道独立处理这些报文,进入网络控制协商阶段以前的PPP协商报文都是在MP各通道上处理,最典型的有PAP、CHAP等验证报文。
2.3.2 NCP报文的发送与接收
MP中NCP的报文的发送与接收是以MP链路为单位的。一条MP链路的一种NCP对应一个NCP状态机。在NCP看来MP链路是一个整体,它与MP下各通道是隔离透明的,不关心报文在哪个通道接收与发送。NCP报文是否要用MP头去封装发送,从实现上讲,可以这样做,但一般实现都不会这样做,没有意义。
那用MP头封装后的NCP报文能否被对端正确接收处理呢?这与厂家的实现相关,有些厂家对这种报文没有做出正确处理。
NCP报文不一定非要在第一个LCP UP的通道上发送;但多数厂家使用第一个LCP UP的通道发送。
2.3.3 网络层报文的发送与接收
MP链路上网络层报文的发送有多种策略,可以采取轮转法,在MP各通道上轮流发送,也可以搞点智能的东西,考虑各通道的带宽、时延等,根据这些参数选择不同的通道发送。发送的报文也有不同的策略,可以不分片,甚至可以不封装MP头,直接在上面发送网络层报文(当然,这样就不能分片了,这是大多数高端路由器高速口上采取的发送策略),当然也可以MP分片,分片可以限制分片个数,可以限制分片大小。
MP的接收是被动的,因此谈不上什么策略,但实现的方式却也是各种各样。有的是依据RFC1990严格实现(如Linux内核的实现),有的容错性更好些(如H3C产品),分布式MP的实现种类就更多些了。不过,总的依据是MP报文格式,基于MP报文格式实现组装策略。
MP报文格式里面主要有首片标志B,尾片标志E,以及序号S这三个属性字段。IP报文的组装依赖的主要是标识、长度、偏移量。比较而言,MP报文里面缺少的主要是标识,有不少人抱怨设计MP的人太抠门,舍不得给个标示字段。可能设计者考虑的更多的是IP是个广域网,其传输的可靠性要大打折扣,而MP是点对点的链路传输毕竟要可靠些,分片丢失的可能性是比较小的。事实也是如此,频繁的MP分片的丢失会导致MP链路的极其低效。一个好的系统会尽可能做到MP的分片不丢失,分片不乱序,逐流发送、逐包MP发送也是出于这些目的。
MP组包处理策略一般是:收到一个MP分片后,看是否是一个整片(B、E标志都有),如果是则不用组装,去掉MP头直接递给网络层;如果不是整片,则遍历一个MP分片队列,看从首片到尾片是否都收齐了(即首尾片之间不能少一个序号),收齐则上交,否则入队列。什么时候清这个队列,有使用定时器的,也有用覆盖策略的。
2.4 MP链路上对MTU的处理
下面根据MP的情况,介绍一下MRRU、MRU、MTU之间的关系。
RFC1990曾提到过MP中LCP协商的MRRU就相当于MP链路的MRU,那么我们是否可以完全按照这个MRRU来设定发送端的MTU呢?按照MRRU的解释,MP链路的发送端可以发送大小小于这个MRRU的报文,但实际上这又具体取决于发送端的发送策略以及所使用的发送通道(该发送通道上LCP协商好的MRU值也必须被考虑)。
基于上述考虑,一般一条MP链路上的MTU的取值基于下面的公式:
MINMRU = MIN(本端MRU,对端MRU)
MINMRRU = MIN(本端MRRU,对端MRRU)
MTU =MIN(配置MTU,MIN(MINMRU,MINMRRU))
如果,MP通道是PPPoX之类的链路, MTU还要考虑X的MTU了,就更复杂了,因此有的厂家,在这些情况下,干脆将MTU跟着配置的MTU走,实际上也是一种比较实际的策略。
2.5 MP报文格式

图4 MP的帧格式
PPP帧格式是以0xFF,0x03 标识,MP报文封装是以 0x00,0x3d 所标识,MP头为4个字节,其中包括两位 B /E 标识报文的开始及结尾,其余位是为今后预留;24位的长序列号,在PPP的子通道协商后也有可能是长序列号也有可能是2个字节的短序列号,H3C产品默认是长序列号实现。

图5 长序列号报文格式
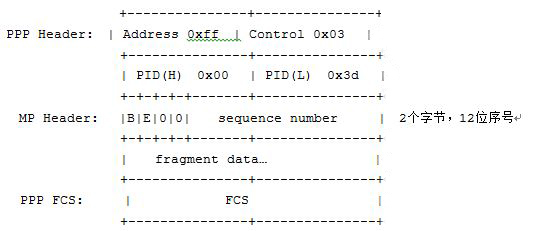
图6 短序列号报文格式
2.6 MP分片
H3C产品有关MP的分片实现算法为:
([报文长度/MP分片长度]+1)=X,然后Y=MIN(X,捆绑数,16),Y就是所分片的个数。
例如,3条链路捆绑,MP分片长度为200byte,发送长度为800byte的报文时,X=([800/200]+1),Y=MIN(5,3,16),应分为3片报文。
2.7 PPP MP LFI 链路分片与交叉
在低速串行链路上的实时交互式通信,如Telnet和VoIP,往往会由于大型分组的发送而导致阻塞延迟。例如,正好在大报文被调度而等待发送时,语音报文到达,它需要等该大报文被传输完毕后才能被调度,这会导致对端听到话音的断断续续。
交互式语音要求端到端的延迟不大于100~150ms,一个1500bytes的报文需要花费215ms穿过56Kbps的链路,这超过了人所能忍受的延迟限制。为了在低速链路上限制实时报文的延迟时间,需要一种方法将大报文进行分片,将小报文和大报文的分片一起加入到队列。
LFI(Link Fragmentation and Interleaving,链路分片与交叉)将大型数据帧分割成小型帧,与其他小片的报文一起发送,从而减少在速度较慢的链路上的延迟和抖动。被分割的数据帧在目的地被重组。
图7描述了LFI的处理过程。大报文和小的语音报文一起到达某个接口,将大报文分割成小的分片,如果在接口配置了WFQ(Weighted Fair Queueing,加权公平队列),语音包与这些小的分片一起交叉放入WFQ。
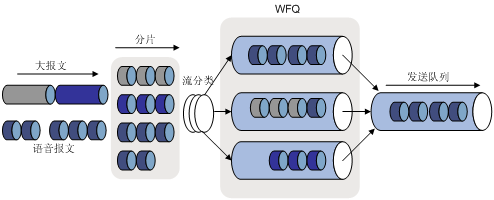
图7 LFI分片处理过程
对于一个给定的抖动目标与链路速度,以下公式可用于决定最大分片大小(字节数):
分片大小 =(允许抖动最大毫秒数)*(链路速度[Kbit/s])/ 8
允许抖动最大毫秒数默认值为10。
例如:允许延时大小为40毫秒,链路为128K,允许的最大分片为:
(40*128)/ 8 = 640字节