


 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友流量监控-独步天下经验篇
配置和排错篇中已经对NTA/UBA结合设备做流量分析和用户行为审计的典型配置和排错思路有了详细的介绍,那么设备上的日志是怎么生成的呢,日志在从设备到NTA/UBA服务器的这个过程中是怎样被处理以及NTA/UBA页面是怎样将这些数据显示到iMC前台的呢,这一招就对此做一详细的说明。并将整个流程中可能会出现的问题进行细致的分析,以便大家能够对流量监控方面的原理有一个清晰地理解。
1. 设备上netstream日志生成过程详解
在设备接口下开启netstream功能后,当有报文从此接口转发时,那么netstream处理模块就会先将此报文引入netstream cache中分析并同时创建一个关于此条流的记录(entry),然后将报文交给转发模块进行转发。而当后续具有相同源地址、源端口、目的地址、目的端口、协议、TOS、输入接口、输出接口(7元组相同的报文成为一条“流”)的报文再次流过时就在这个记录中进行+1操作,以此方式来实现对每条流的统计。当同一条流的第一个报文到达接口,经过active time 时间后就会结束关于这条流的统计,并将统计结果以netstream UDP报文的方式输出,或者是同一条流的最后一个报文到达后,经过inactive时间还没有再次收到这条流的报文时就结束关于这条流的统计,并将统计结果以netstream UDP报文的方式输出。这分别称为active老化和inactive老化。设备上默认会同时有active time 和inactive time 配置,当有其中一个满足之后就会结束本次统计进行结果输出。多条流的统计结果可以以一个UDP报文发送。如果配置了采样功能的话,那么netstream处理模块就不会将流中的每个报文都引入netstream cache进行分析了,只会在同一条流中“挑选”出部分报文进行分析统计,以此来提高netstream模块的处理速度,这里可以配置根据报文数采样或者根据时间间隔来采样。当配置了聚合功能后,那么分析过程还是原来的步骤,但是在统计分析结果时就会将具有相同聚合条件的流的统计结果合并来发出一个总的统计结果,以此来减小netstream模块的发送压力。Netstream日志生成的大致过程可参考下图1:
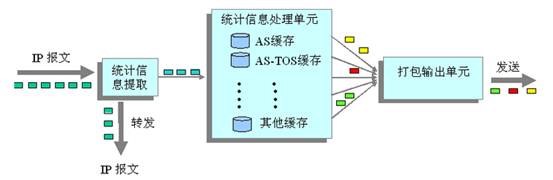 图1
图1
2. 在NTA/UBA服务器抓包可以抓到设备发送过来的日志报文,但是receiver进程却没有收到并在receiveData目录下成功更新生成.csv格式文件的问题分析
抓包软件直接侦听的是物理网卡的报文收发情况,但是上层软件实际能接收到的报文是要经过操作系统处理后上送上来的数据,所以如果服务器本身开启了防火墙并过滤掉了日志报文,那么就可能会出现这种现象。报文已经到达了服务器,但是却被服务器丢弃掉了。所以请排查服务器上是否开启了防火墙并配置了过滤日志报文的入站规则。
3. 在NTA/UBA服务器上抓包时抓到的包不光有设备发往服务器的UDP报文还有服务器回复给设备的ICMP报文,如下图2:
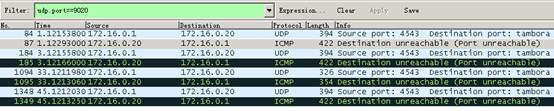
图2
这种情况通常是由于NTA/UBA服务器的receiver进程没有启动,侦听端口9020没有打开,所以设备发往服务器UDP 9020端口的报文被返回目的不可达信息。请查看部署监控代理并重新启动receiver进程即可。
4. 设备配置的日志报文源地址与NTA/UBA添加设备时选择的日志发送源地址之间的关系
NTA/UBA设备管理页面中会为设备指定一个日志发送源地址,以此来判断后续收到的日志是不是属于这台设备的,如果该设备发送日志时却配置了不同的源地址,那么服务器就会认为没有收到这台设备的日志,从而也就无法统计出这台设备的流量信息,所以请一定确保这里配置的日志源地址与设备上配置的日志发送源地址一致。
5. NTA/UBA组件支持多分布式部署,也就是可以在多台从服务器上同时部署NTA/UBA组件,后续设备日志的发送目的地址也应该为从服务器的地址,并且receiveData文件夹也是存在于对应的从服务器上。分布式部署时主服务器和从服务器上的部署监控代理中都会出现NTA/UBA的进程,如果需要启动进程时应该在相应的从服务器上启动,如下图3:
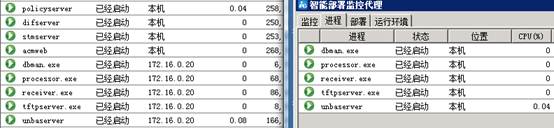
图3
6. 通常我们都会在NTA/UBA服务器上进行抓包来判断是否获取到了日志报文,下面介绍如何对抓到的包进行分析
Netstream V5报文
以udp.port==9020为条件过滤出UDP端口为9020的报文,右键decode as选择CFLOW,即可正确解析netstream V5报文,如下图4:
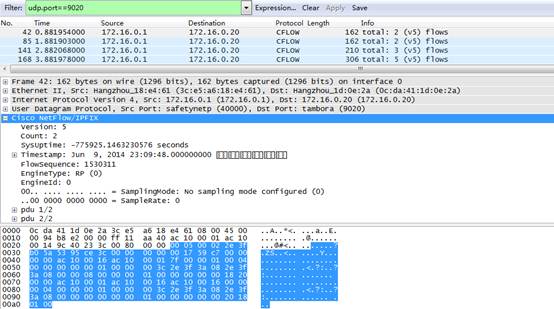
图4
Version:表示此netstream报文采用的版本,目前netstream支持V5,V8,V9三个版本。V5是标准的报文格式,V8支持对聚合流量的统计,V9支持自定义模板来使报文中可以携带更多的内容。
Count:表示此netstream报文中共有多少条流的统计结果,后面每一个pdu就记录了一条流的统计结果。图中数值为2,表示这个netstream日志报文中一共包含两条数据库的统计数据。
SampleMode:表示此netstream配置的采样功能,图中所示no sampling mode config表示没有配置采样,那么流中的每个报文都会被引入netstream cache进行分析统计。
接上一图分析pdu部分,可以看到其中具体的内容,通过这些内容我们就可以知道每条流的详细信息,如下图5:

图5
SrcAddr:表示流的源IP地址,主要用于基于源主机的流量分析
DstAddr:表示流的目的IP地址,主要用于基于目的主机的流量分析
InputInt:表示流的入接口
OutputInt:表示流的出接口
Octets:表示此次分析了数据流中的多少个报文,通常这个字段可以用来分析存在流量但流量不准的情况,netstream处理过程中会记录当前流中报文的大小分布情况如下图6,通过这些报文大小分布和总报文数就可以计算出一段时间内流量的大小。

图6
Srcport:表示流的源端口
Dstport:表示流的目的端口
Padding:表示此次统计是对接口的出方向有效还是入方向有效,00表示对入方向有效,01表示对出方向有效。由于流是一个单方向的概念,所以在统计时就需要指定这条流是入方向的还是出方向的,以此来区分统计接口的接收流量和发送流量。
通过以上分析,可以确定图中流为从172.16.0.22:0到172.16.0.1:2048,只对0口的入方向有效的。
Netstream V9报文
以udp.port==9020为条件过滤出UDP端口为9020的报文,右键decode as选择CFLOW,即可正确解析netstream V9报文,如下图7:
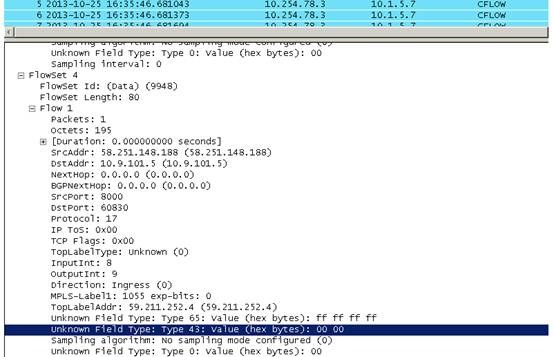
图7
Octets表示数据流的字节数,这个一般用在存在流量,但是流量不准的情况下。可以以此结合流中报文大小的分布情况计算出流量的大小。
SrcAddr表示会话五元组中的源IP,DstAddr表示会话五元组中的目的IP,这个一般用在基于主机的流量分析任务中无数据的情况。
SrcPort和DstPort则表示会话五元组中源端口/目的端口。
inputint/outputint则表示该条流在设备上的哪个口接收哪个口发送。
Direction表示该流的方向,分为(00)入和出(01)。如果为入,则表示该流只针对入端口有效,如果为出,则表示该条流只针对出端口有效。
unknown Field Type则表示VPN ID,这个主要应用与VPN流量分析任务无流量的问题,该处是十六进制的,需要转换为十进制数据。
通过以上分析,可以确定图中的流为
从58.251.148.188:8000到10.9.101.5:60830,只针对8口的入方向统计有效。
Sflow报文
以udp.port==9020为条件过滤出UDP端口为9020的报文,右键decode as选择SFLOW,即可正确解析sflow报文,如下图8:
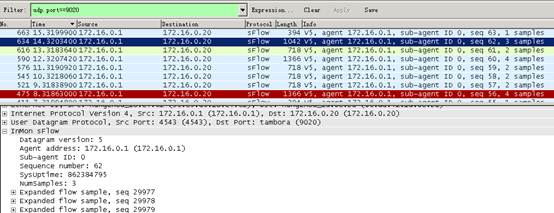
图8
Datagram version:表示此sflow报文的版本,目前sflow有V4和V5两个版本。
Agent address:表示发送此报文的设备上的sflow agent地址,一般也就是sflow报文的源地址。
Sequence number:表示此报文的顺序号,正常情况下sflow报文的顺序号应该是按照到达时间逐个加1的,依此我们可以判断sflow报文在发送过程中有没有出现丢包的问题,确定统计结果是否准确。
Numsamples:表示此sflow报文中共包含多少个流的分析结果,图中数值为3表示此次记录了3个数据流的采样分析结果,对应下面的3个Expanded flow sample。
Expanded flow sample:叫做扩展的流采样,里面记录了对数据流的统计分析结果。目前sflow共有两种采样模式,一种叫做flow采样,一种叫做counter采样,这里就是flow采样的结果,目前NTA/UBA只支持flow模式的采样。
接上一图分析Expanded flow sample部分,如下图9:

图9
Sampling rate:表示sflow的采样速率,图中1 out of 1000表示采样速率为1000个报文中采集一个报文。
Input interface value:表示流的入接口
Output interface value:表示流的出接口
其他字段记录了此条流的其他相关信息,比如Extended router data记录了流中报文的路由信息,Ethernet frame data记录了流中报文的链路层信息。
IPv4 data:记录了流的IP层信息,如下图10:
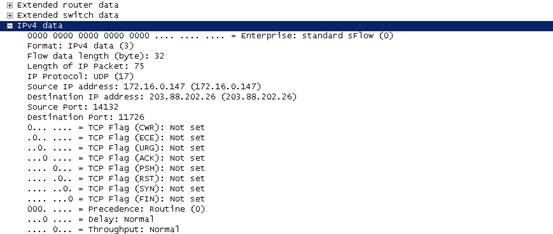
图10
IP protocol:表示IP报文中数据部分的协议,图中UDP表示此条数据流是一个UDP数据流。
Source IP address:表示流的源地址
Destination IP address:表示流的目的地址
Source Port:表示流的源端口
Destination Port:表示流的目的端口
通过以上这些分析我们可以确定图中的数据流为
从172.16.0.147:14132到203.88.202.26:11726,是一种UDP报文,在此设备转发时是从接口0流入从接口4流出的。
7. NTA/UBA在接收并且正确处理完日志报文后会将处理结果保存在数据库中,以便后续前台进行调用展示,下面分别对数据库中不同的表进行介绍
*tbl_nets_*:此表以日期为后缀,保存的是服务器接收到的原始流日志信息,在做用户行为审计时调用的就是这些表里面的数据。由于此表中一般记录的数据量非常大,所以V7版本时如果只部署了NTA组件默认是不会创建此表的,需要在服务器管理页面配置开启“原始日志捕获”功能,但也只会捕捉到后续2个小时内的数据,如果部署了UBA组件时则一直会创建此表并记录原始流日志,具体的表内容如下图11:
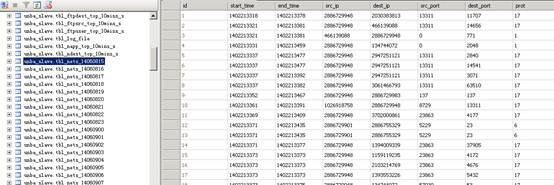
图11
这些表是以小时为单位创建的,右键“编辑前1000行”即可看到此表中的内容,里面详细列出了每条流的id,开始时间,结束时间,源端口,目的端口等信息,可以此判断NTA/UBA服务器后台有没有正确统计到数据,如果在做行为审计时,审计出来的结果页应该和这里是一致的。比如这里的2014060815表中有500条记录,那么用户行为审计审计2014.06.08:15:00到2014.06.08:15:59期间的结果也应该是500条。
*tbl_flux*_*:此表是NTA/UBA对原始日志分析处理后的流量汇总数据,以if,vlan,vpn等为后缀,表示接口任务下的流量大小,vlan任务下的流量大小,vpn任务下的流量大小等。如果在接口任务下没有流量显示,则需确认*tbl_flux*_if表中是否存在数据,如果vlan任务下没有流量显示,则需确认*tbl_flux*_vlan表中是否存在数据,以此类推。具体的表内容如下图12:
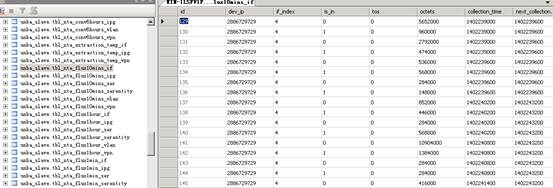
图12
*tbl_app*_*:此表是NTA/UBA对原始日志分析处理后的应用流量汇总数据,以if,vlan,vpn等为后缀,表示接口任务下的应用流量情况,vlan任务下的应用流量情况,vpn任务下的应用流量情况等。如果接口任务下选择“应用”页签发现没有流量显示,则需要确认*tbl_app*_if表中是否有存在数据,如果vlan任务下选择“应用”页签没有流量显示,则需要确认*tbl_app*_vlan表中是否存在数据,以此类推。具体的表内容如下图13:
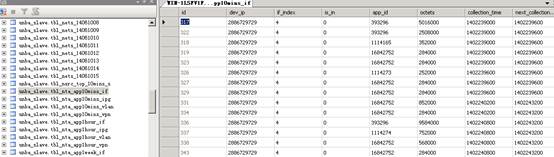
图13
*tbl_conv*_*:此表是NTA/UBA对原始日志分析处理后的会话流量汇总数据,以if,vlan,vpn等为后缀,表示接口任务下的会话流量情况,vlan任务下的会话流量情况,vpn任务下的会话流量情况等。如果接口任务下选择“会话”页签发现没有流量显示,则需要确认*tbl_conv*_if表中是否有存在数据,如果vlan任务下选择“会话”页签没有流量显示,则需要确认*tbl_conv*_vlan表中是否存在数据,以此类推。具体的表内容如下图14:
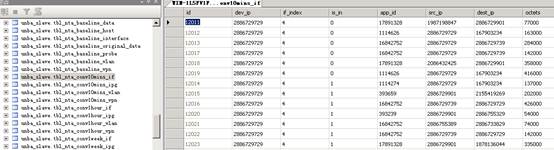
图14
注:NTA/UBA服务器接收的通常都是大量的日志数据,为了减轻对磁盘存储的压力,服务器会将接收到的数据进行聚合处理,通常是十分钟内的原始数据处理后存为一个10mins的数据,六个10mins的数据聚合成一个1hour的数据,六个1hour的数据聚合成一个6hour的数据,四个6hour的数据聚合成一个1day的数据,七个1day的数据聚合成一个1week的数据。而在不同的审计周期内前台调用的表也是不一样的,在查看最近一小时流量时调用的是原始的数据,在查看最近3小时流量时调用的是也是原始的数据,在查看最近12小时的流量时调用的是10mins的数据,在查看最近24小时流量时调用的也是10mins的数据,在查看最近一周流量时调用的是6hour的数据,在查看最近一月流量时调用的是1day的数据。所以在排查流量无法显示查看数据库时也应该按照不同的审计周期区查找不同时间精度的表。在统计页面中我们也可以看到本次审计的具体时间精度情况,如下图15:
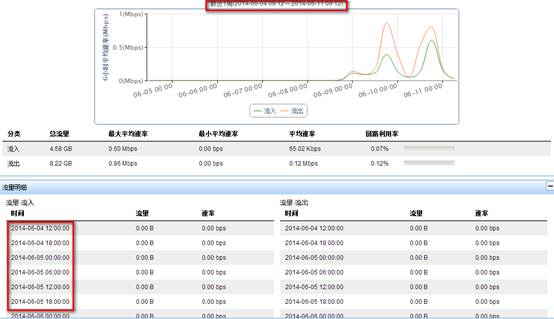
图15
8. 在数据库中已经有数据存入后一般情况下就可以在页面正确显示了,如果此时还是看不到流量统计情况,那么就需要收集以下前台日志,查看前台在调用后台数据时是否出现的问题,今天的前台日志存储位置imc\client\log\下的imcforegroud.log(带日期后缀的为对应日期的)