


 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友北冥有鱼,其名为OCFS2——集群主机重启分析
一、 集群主机重启分类
1. 人为手工重启
管理员在服务器操作系统上执行了reboot命令,或者在Flexserver服务器的remote console上执行了重启操作。
2. 服务器部件问题导致重启
服务器主机重启也有可能和服务器硬件存在关系,比如服务器的BIOS、主板、风扇、电源、阵列卡等部件存在固件版本问题或硬件故障都有可能导致服务器重启。通过查看服务器指示灯和登录相应服务器iLO查看相关日志进行问题定位和分析。
3. 共享文件系统导致重启
由于共享文件系统的机制,当主机与存储链路不通或者挂载同一共享存储的主机之间的共享文件系统心跳报文不通都会造成该主机重启。本文主要对该机制进行分析。
二、 共享文件系统引起主机重启机制
1. 与存储链路不通
1) 若主机与存储之间的链路不通,则60秒后主机重启。
2) 主机重启后,若依然未与存储连通,则将共享文件系统置于不活动状态。
2. 主机之间共享文件系统心跳报文不通
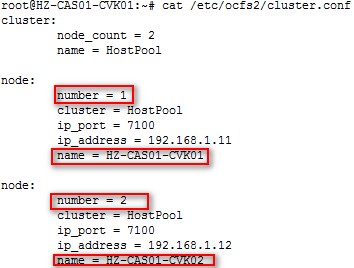
首先介绍共享文件系统编号,共享文件系统是以主机池为边界的,共享文件系统的集群名称就是主机池的名称。查看主机共享文件系统节点号的命令为:
cat /etc/ocfs2/cluster.conf
如下图:node_count表示集群节点数,主机池(共享文件系统集群)名称是HostPool,HZ-CAS01-CVK01是节点1,HZ-CAS01-CVK02是节点2。
共享文件系统机制中主机参与节点判断方法:
l 主机池中共有T台服务器,其中m (1≤m≤T)台服务器挂载同一共享文件系统(均为“活动状态”),则该共享文件系统的node_count=m
l 有n (1≤n≤m )台服务器共享文件系统状态为不活动,则node_count=m-n
l 有p(1≤p≤m)台服务器处于关机或重启过程中,则剩余服务器每隔2s同步共享文件系统心跳时会自动去除这些服务器,即此时的node_count=m-n-p
下面介绍node_count数量不同的情况下,主机重启的规则。
1)主机数量为奇数:
l 某主机无法连通的主机数量大于等于(node_count+1)/2,则该主机重启,否则不重启;
2)主机数量为偶数:
l 某主机无法连通的主机数量大于node_count/2,则该主机重启;
l 某主机无法连通的主机数量等于node_count/2,则集群编号为1或与1连通的主机不重启,否则重启;
三、 不同场景主机重启举例分析
云计算网络组网要求三网分离,即管理、存储、业务网分离。管理、存储可以在同一个交换机上通过不同vlan来隔离也可以接入到不同交换机进行隔离。下面分析不同数量主机下主机重启的现象。
1. 两台主机挂载共享文件系统
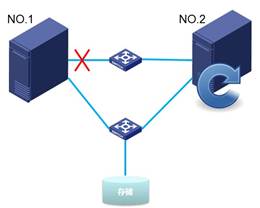
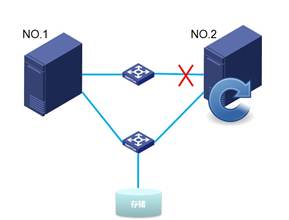
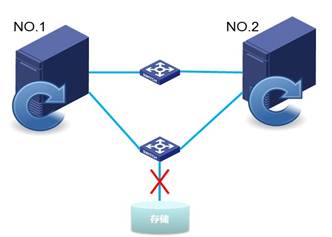
如下两图,2台主机管理网通过交换机互联,并且都通过交换机与存储互联。主机1的集群编号为1,主机2的集群编号为2。
当主机1与主机2之间管理网断开连接,则会发生主机2重启现象。
当主机1和主机2都与存储断开连接,则会发生主机1和主机2都重启现象。
2. 三台(及以上)主机挂载共享文件系统
如下两图,3台主机管理网通过交换机互联,并且都通过交换机与存储互联。
当主机1管理网或存储网与交换机断开连接,则主机1重启。
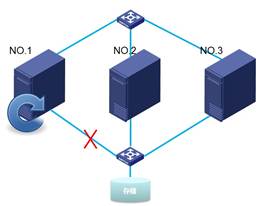
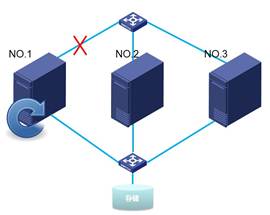
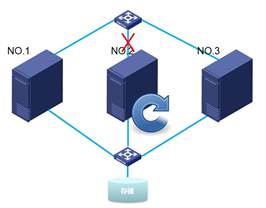
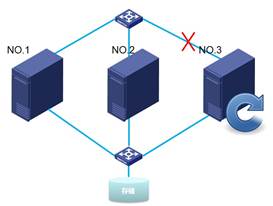
而当主机2或主机3和上述情况一样发生存储网或管理网连接断开,也会发生各自的重启。如下分别为主机3和和主机2重启。
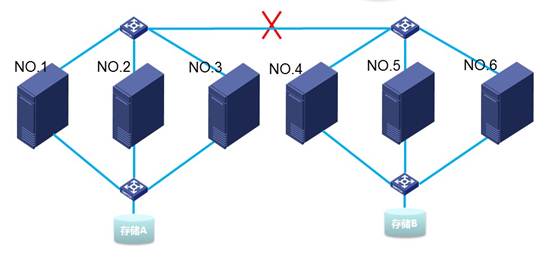
3. 六台主机挂载共享文件系统(特殊组网)
1)如下图所示,六台主机,2个共享存储,其中1-3连接共享存储A,4-6连接共享存储B,交换机之间出现链路问题,那么主机都不会发生重启。原因是只有使用了挂载相同的共享存储,节点间才有心跳检测。
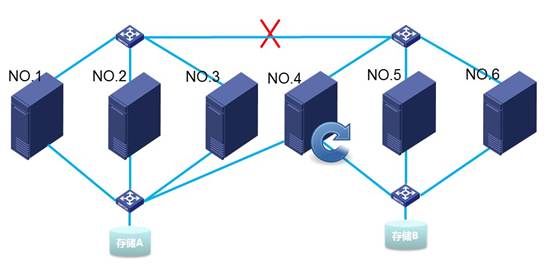
2) 稍微变更组网,将4挂载上共享存储A,那么当交换机之间链路故障,会发生4重启,5、6不重启的现象。(实际组网不推荐)
四、 主机由于共享文件系统机制重启的问题日志分析方法
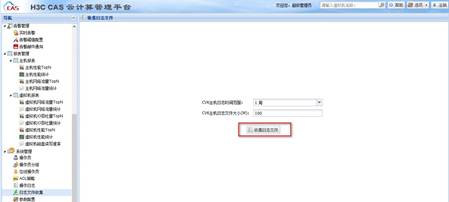
当发现了主机重启后,可以收集CAS日志进行简单的分析判断。
收集日志方法为:导航栏-系统管理-日志文件收集
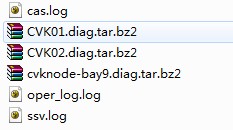
日志解压后,如下图:
下面,我们开始分析日志。
1)确认重启的主机
查看oper_log.log文件,看到如下虚拟机迁移信息(若已开启了HA),可以判断CVK01上的虚拟机迁移到了CVK02,那么可以判断CVK01发生了重启。没有开启HA是不会有迁移信息的,需要人为判断。

2)分析主机重启原因和故障时间
解压CVK01的压缩包,找到目录下的文件CVK01.diag\logdir\var\log中的ocfs2_shell_201XXX.log的文件,该文件记录了共享文件系统的相关日志信息,如下:
2014-05-27 04:59:06 util_common_tools.py/53L: ERROR:Command '/lib/udev/scsi_id --whitelist -u /dev/disk/by-path/ip-172.19.209.148:3260-iscsi-iqn.2003-10.com.lefthandnetworks:class:56:cvk-lun-0' returned non-zero exit status 1
2014-05-27 04:59:06 ocfs2_pool_info.py/96L: WARNING:get device:/dev/disk/by-path/ip-172.19.209.148:3260-iscsi-iqn.2003-10.com.lefthandnetworks:class:56:cvk-lun-0 scsi_id failed
2014-05-27 04:59:23 util_common_tools.py/53L: ERROR:Command '/lib/udev/scsi_id --whitelist -u /dev/disk/by-path/ip-172.19.209.148:3260-iscsi-iqn.2003-10.com.lefthandnetworks:class:72:jlb-one-lun-0' returned non-zero exit status 1
2014-05-27 04:59:23 ocfs2_pool_info.py/96L: WARNING:get device:/dev/disk/by-path/ip-172.19.209.148:3260-iscsi-iqn.2003-10.com.lefthandnetworks:class:72:jlb-one-lun-0 scsi_id failed
2014-05-27 05:05:02 ocsf2_pool_info.py/58L: WARNING:Pool name is None or length is zero
我们可以看到iSCSI存储连接中断,(若为FC存储,也会有相应的FC信息显示failed)而其所对应的时间与之前看到的虚拟机发生迁移的时间吻合。
3)通过syslog判断主机重启时间
下面我们再查看另一个日志文件syslog,该文件有多个,分别以.1、.2结尾(后缀数字越小代表时间越新),如下图:
推荐使用UltraEdit软件(文本文档也可)打开该文件,找到对应的时间的日志,可以看到有很多共享文件系统报错:

日志再往下看,可以看到主机重启的信息:
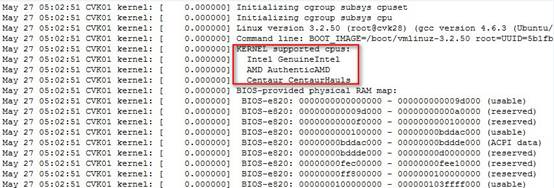
到这里,我们可以判断该主机重启是因为共享文件系统机制导致,其与存储发生了连接中断。而连接中断的原因,需要继续排查主机与存储之间的链路问题,这些问题都可以在交换机上进行相应的排查,不再详述。
五、 总结
主机发生重启,在排除掉人为原因和主机本身问题后,我们可以通过主机总数量和发生重启的主机数量来判断重启原因,若只有一台主机重启,则可能为该主机管理网或存储网链路问题。若达到半数主机重启,则可能为主机之间的管理网链路问题或者该半数主机与存储之间的链路问题。若所有主机重启,则可能为存储到交换机之间链路问题。