


 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友MPLS VPN技术企业组网应用分析
文\肖春喜
一些大型企业组建基于MPLS VPN的网络是为了满足业务隔离的需求,针对客户的需求,我们讨论一下如何部署MPLS VPN网络并运用基于MPLS VPN的各种技术来实现客户的需求。
根据组网模型和需求,需要考虑的部分包括MPLS VPN技术中应用的方式和方法,设计时我们将MPLS VPN中的技术进行分解来说明所涉及的技术应用。
1. IP地址的规划问题
MPLS VPN技术,它本身是可以解决不同VPN的地址重叠问题。但在企业的实际组网中,出现地址重叠的情况比较少,因此在部署IP地址时,可以不去考虑地址重叠的问题。IP地址的设计一般有两种方式:一种是先将地址按业务进行横向分类,再按地域纵向分类;另一种是将地址先按地域横向分类,再按业务纵向分类。从网络运用的合理性来看,前一种方式显然更合理,因为它更有利于地址的聚合,对业务的扩展性较好;而后一种方式对于有些用户来说方便管理,从地址能直观识别出所属地域的特性。这些都是使用习惯问题,一般没有强制要求。
2. IGP协议的选择
在MPLS VPN体系结构中,IGP的主要作用是保证BGP对等体的可达性以及MPLS隧道的建立,在这一点上与普通的BGP组网中原理是一致的。和纯粹的IP网络不同,大部分情况下MPLS VPN体系结构中的IGP不带任何客户的VPN业务,IGP路由是为了建立BGP连接和交互协议报文,因此有较多的选择。一般而言,推荐采用收敛速度快、路由振荡少、基于SPF算法的路由协议,如OSPF、IS-IS等;在部分环境中,也可以使用静态方式。IGP的另一个功能是驱动公网标签分配,以建立MPLS隧道。MPLS VPN网络中数据流的转发是基于标签的,如何让设备的标签能够正确分配,IGP协议居功至伟。
在规模较大的网络中,如果采用OSPF作为IGP,并且需要划分区域进行管理时,不要使用stub、totally stub、NSSA区域等优化应用措施;如果采用IS-IS作为IGP,在区域分级时需要将level-2中的设备loopback接口地址段引入到level-1中。
MPLS的配置中有一条命令是lsp trigger-all,这条命令的目的是为所有的IGP路由分配标签。我们知道MPLS隧道的起点和终点都是LSR的LSR-ID(一般是设备的loopback接口),因此无须为每一条IGP路由都分配标签。默认配置下只为32位主机地址分配标签,这样就可以满足MPLS VPN的部署需要了。所以建议不要使用该命令,以免造成对标签空间不必要的浪费。
3. 针对MPLS VPN的应用
从企业组网的需求来分析,MPLS VPN的组网应用分为2个层次,域内(inter AS)MPLS VPN的规划和域间(intra AS)的规划设计。从技术角度分析,两者有共性的东西,也有相异性,在应用时我们按inter AS和intra AS来分析应用。
3.1 域内MPLS VPN的规划
3.1.1 业务的命名
实际组网中业务的命名通常采用业务的拼音字母或是英文名,只要不重复就行。我们假设客户需要3个VPN,命名为sale,finance,manage。
ip vpn-instance sale
ip vpn-instance finance
ip vpn-instance manage
3.1.2 RD的定义
从原理上讲,RD的作用是将IPv4的地址变成全局唯一的VPNv4的地址,当不同VPN内出现重叠的IPv4地址时,RD可以将他们区分开来。采用格式通常为ASN :N方式,也有使用基于IP地址格式的,如X.X.X.X:N,不过后者不常使用。所以只要VPN地址不发生重叠,RD可以任意搭配。根据网络特点,我们采用ASN :N方式,用本AS号+N(N可以任意取值),一般在同一个VPN中使用相同的RD是较为常见的做法。
所以RD定义:
vpn-sale | RD=ASN :100 |
vpn-finance | RD=ASN :200 |
vpn-manage | RD=ASN :300 |
ASN为本AS的编号
3.1.3 RT的定义
RT在MPLS VPN中作用非常明显,它用来控制VPN的隔离和部分互通,格式与RD相同。对不同的VPN,要求定义不同的RT的值,如果有互通需求,通过RT的属性来控制,分为export和import属性。export属性代表发送VPN路由时附带的属性,当另一PE设备收到此路由,通过import属性来决定接收与否或是接收时与哪个对应的VPN关联。所以针对VPN的定义,如果三个VPN不要求互通,那么:
vpn-sale | export =ASN :100 | import=ASN :100 |
vpn-finance | export =ASN :200 | import=ASN :200 |
vpn-manage | export =ASN :300 | import=ASN :300 |
3.1.4 PE-CE间路由的规划
PE-CE之间的路由协议,不同于PE-PE之间的IGP路由,PE-CE间的IGP是传递VPN路由的,并且PE会将这些VPN路由通过BGP来发送。所以PE-CE之间的路由选择应该根据实际需要来使用,可选择直连,静态,OSPF,RIP,IS-IS或是EBGP。在使用中需要特别注意一点,所有的路由都是基于实例(vpn-instance)的,在不同的VPN中可以采用相同类型的路由协议,最终被import到MP-BGP中。因此要求PE设备对路由协议的支持要丰富,多实例是最基本需求。从组网中的双归属特性来看,采用OSPF或是EBGP比较合适(在企业网中使用IS-IS的情况比较少)。从减轻网络的复杂程度来看,使用OSPF比较通用。
在规划部署OSPF区域的时候,整个MPLS核心骨干被看做一个SuperBone,PE-CE之间的区域则属于普通的骨干或者非骨干区域。如果在不同site的位置上,PE-CE之间运行完全不同的OSPF进程,那么除了多实例的要求外,Domain ID的规划也是重点考虑的条件之一。
同时,为配合双规属的要求,在将BGP注入到OSPF时,对于cost值的灵活应用也是很重要的。按照应用需求,在CE双规属到PE上时,如地区公司CE到地区公司的PE上行时,要求负载分担,在PE上OSPF注入BGP时,可设置相同的cost值,如果要求针对不同网段选择不同的PE设备,另一PE设备作为备份使用时,可通过设置不同的cost值来实现。
3.1.5 PE-PE之间IBGP
PE-PE的IBGP,是对BGP4协议的扩展,对BGP4是完全兼容的,所以相关的路由策略设计也是相同的。尤其是在选择路径的策略和原则上,这是BGP的魅力之一。不同的是将原有普通的BGP路由变成带有VPN属性的BGP路由。对于路由的选路控制充分利用Local-Preference和MED属性,Community属性来实现。当缺省不作设置时,应该充分利用BGP中对于loopback地址这个下一跳和IGP的优选路径的依赖来实现业务的分流。
3.1.6 关于多角色主机
此功能在网络中应用比较广泛,主要应用于某个特定的VPN中用户,有较高的权限访问多个或者所有VPN中的业务,是一种新的技术实现手段。传统的技术手段包括:更改原有的拓扑结构,采用类似Hub-Spoken的组网技术,或是采用RT值的配对来控制路由的分发。多角色主机的技术是对传统技术手段一种较好的补充。它在发送时,采用策略路由的方式,强制进入它希望的VPN中,在返回的报文,采用静态路由的方式连续在不同的VPN中强制定义返回VPN的下一跳来实现访问。这个功能特性大大减轻了对设备的压力,并能很好的实现访问多个VPN的需求,多用于网管服务器对所有VPN中CE的管理或是超级用户对VPN的访问。
3.1.7 HoPe的应用
当网络规模较大时,在同一AS中,所有的PE设备因为采用IBGP的连接,因此维护路由的总量是相同的,同时对于标签的消耗也是相同的。但网络毕竟有层次之分,在接入层的设备由于硬件和软件功能特性的原因,不能承担大量的VPN路由,这样就会出现部署的问题。尤其当接入设备只有一个上行出口时,维护VPN路由更没有必要,这时分层PE的技术较好的解决了这个问题。由SPE向UPE发送相应VPN的缺省路由,尤如OSPF中stub区域从ABR获取了缺省路由一样,减轻了下层UPE设备的压力。在有多个出口的情况下,可以通过BGP的选路和HoPE的配合,减小路由表的容量。HoPE的功能是可以嵌套使用的。
在使用中,我们发现HoPE还有可改进的地方。目前它的实现方法类似于IS-IS中level-2对于level-1中发送缺省路由,这是用户不太希望看到的,希望有控制的发送部分指定路由,这要求实现类似level-2往level-1中的路由泄漏功能,如果分层PE能实现按需由SPE向UPE发送路由,而不是单纯发送缺省路由,这个技术的应用就完美了。
3.1.8 VPN中网管的使用
如果VPN中的网管,只需要管理PE设备,部署非常简单,将网管服务器连接到公网所在接口上,直接在公网的IGP中发布路由。如果还需要管理CE设备,建议采用如下三种方式来实现:
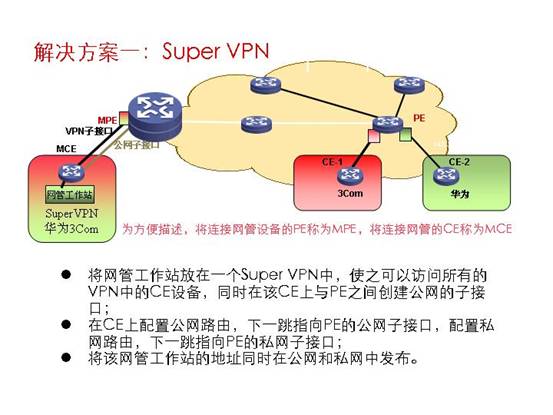
方式一:Super VPN
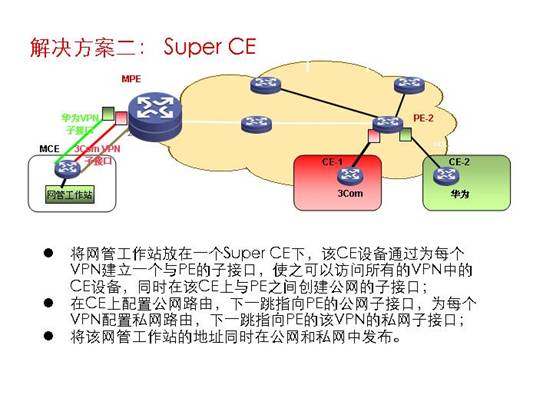
方式二:Super CE
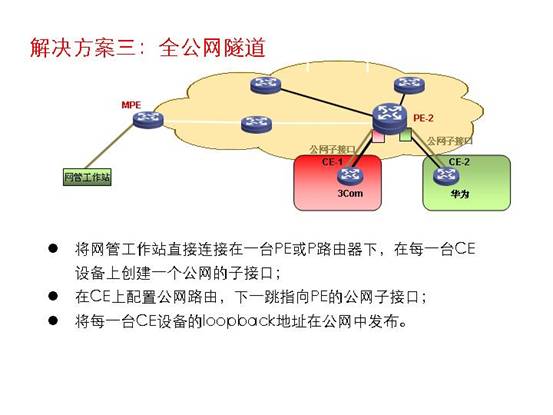
方式三:全公网隧道
上述三种方案的比较:
方法 | 网管设备位置 | 对VPN地址规划的要求 | 对设备的需求 | 路由发布 | 工作量 | 安全性 |
Super VPN | 私网中,与MCE相连 | VPN地址空间不能重合 至少CE的loopback地址不能重合 | 最好是使用单独一台MCE与网管相连 | 只要私网和公网的路由完全分开,可以在MCE上方便地配置静态路由 | 更改所有PE(RT改变)和一台CE的配置(子接口) | 存在不同VPN通过Super Vpn 间接互访的隐患,网管工作站易受到CE中主机的攻击 |
Super CE | 私网中,与MCE相连 | VPN地址空间不能重合至少CE的loopback地址不能重合 | 最好是使用单独一台MCE与网管相连 | 如果私网地址无规律,必须在MPE与MCE之间运行动态路由协议的多实例 | 只更改一台PE和一台CE的配置(子接口) | 存在不同VPN通过Super CE间接互访的隐患,网管工作站易受到CE中主机的攻击 |
全公网隧道 | 公网中,与MPE或MP相连 | 无特殊要求 | 无特殊要求 | 在公网可用动态路由方便的发布CE的loopback地址 | 更改所有PE、CE的配置(子接口)并需要重新分配公网的PE、CE互联地址 | 无 |
3.1.9 与internet互联
PE分布式上internet
l 每个VRF中选择一台PE连接internet,连接该PE的CE上做NAT转换。
l 由该CE发布一条缺省路由给本VPN内的所有CE。
PE集中式上internet
l 选择一台健壮的CE连接internet,并且做地址转换。
l 将该CE所属的VRF配置成可以和所有VRF都互通的超级VPN
l 由该CE发布一条缺省路由给全网的所有VPN的所有CE。
l 由于有超级VPN以及缺省路由的存在,会导致不同的VPN通过超级VPN互访,需要在该PE连接超级VPN的VRF上配置 ACL,丢弃源地址和目的地址都是私网地址的报文。
选择哪种方式?
l PE分布式是运营商常用的,企业网不会使用。
l PE集中式太繁琐(每台PE上都要配置ACL),且不支持VPN地址重叠。
l PE分布式无需ACL,且支持VPN地址重叠。
希望节省资源,选择PE集中式;希望支持VPN地址重叠,选择PE分布式。
3.2 AS之间MPLS VPN的规划
随着MPLS VPN解决方案的越来越流行,服务的终端用户越来越多,规格和范围也在增长。在一个特殊的企业内部的站点数目越来越大,某个地理位置与另外一个服务提供商相连的需求变得非常普遍。比如我们国内运营商的不同城域网之间,或是同骨干网之间都存在着非常现实的跨越不同自治域问题。这些都需要一个不同于基本的MPLS VPN体系结构所提供的互连模型——跨域的MPLS VPN,为了支持服务提供商之间的VPN路由选择信息交换,需要一个新的机制,以便可以穿过提供商间的链路来广播路由前缀和标签信息。但是一般的MPLS VPN体系结构都是在一个自治系统内运行,任何VPN的路由信息都可以在一个自治系统内按需扩散,就是没有提供一个跨域的VPN信息扩散功能。因此,为了支持跨域VPN的需求,就需要扩展现有的协议和修改MPLS VPN体系框架。
目前在组网上有三种主流模型,下面将一一介绍。
3.2.1 VRF to VRF
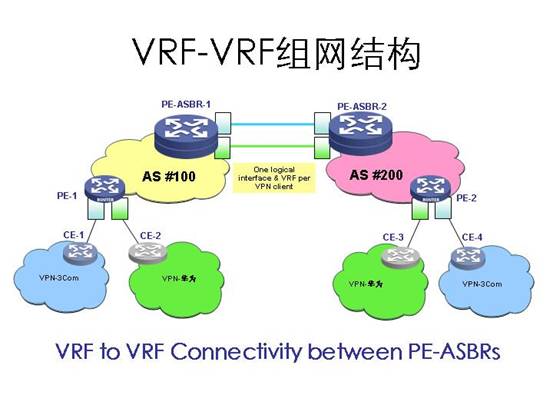
l VRF-VRF解决方案从技术上讲是最简单的,没有在“AS内部的MPLS-VPN”上作任何扩展,完全应用已有技术实现 。
l ASBR对等体间,通过划分子接口方式,每个子接口分别绑定一个VRF,保证域间传播路由的私有性。
l ASBR对等体间,只运行普通BGP,不运行LDP,交互IPV4路由。
l 每个PE-ASBR路由器都把对方PE-ASBR路由器当做CE路由器看待。
l 比较适合运用在AS域间交互VPN(VRF)数量较少的情况。但是扩展性较差。
方案的主要特点:
l 在两个ASBR-PE之间要为不同的VRF建立独立的物理或者逻辑链路(从节省接口的角度考虑,推荐使用逻辑链路),但在企业网中,如果链路是SDH的透明传输,配置起来会比较麻烦。
l LSP的建立:这种方式下PE只要有到本AS内的ASBR-PE的标签就可以了。
l 由于需要在ASBR-PE上为每个VRF配置独立的链路。在VPN数量较多时配置量与BGP的邻居数量是相当大的,所以这种跨域技术只适合VPN数量很少的情况下,适用于一些规模不大的企业网。
l 为了支持不同自治域的VPN互通,必须在ASBR路由器上对应配置相同的VPN,如果跨越多个自治域,配置工作量很大,且对中间域影响比较大,中间域必须支持VPN业务。在VPN数量较多的情况下,在每一个ASBR上的配置工作量也是很大的。
l 这种方案应用非常简单,不要扩展协议和做特殊配置,属于天然支持。在需要跨域的VPN数量比较少的情况,可以考虑使用,属于简单实用型方案。
3.2.2 单跳MP-EBGP的组网应用
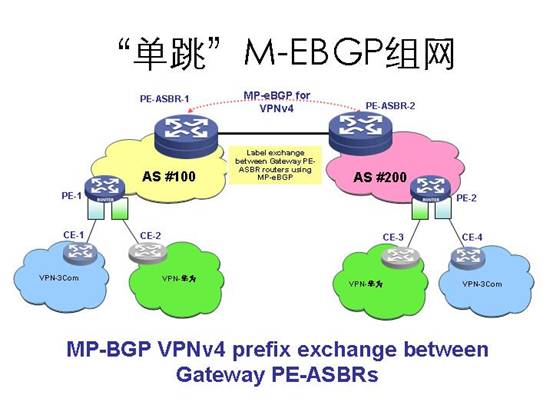
l PE-ASBR对等体之间建立单跳的MP-EBGP邻接体,传递VPN-IPV4路由,不运行IGP和LDP。
l PE-ASBR对等体之间传递私网路由时,因为EBGP邻居关系,需要改变路由的下一跳,所以需要交换内层标签。
l 接收端PE-ASBR,可以使用next-hop-local命令,强制修改路由的下一跳,同时再次交换内层标签,通告给MP-IBGP邻居。如果没有配置next-hop-local命令,需要把direct路由重分布(import-route)到IGP中。
l PE-ASBR路由器上需要保存所有域间的私网路由。对于ASBR路由器来说,压力较大。
l 和VRF-VRF方式相比,具有更好的扩展性。
方案的主要特点:
l 报文转发时,需要在两个ASBR上都要对VPN的LSP做一次交换。有一个需要注意的问题是,这种解决方案需要在ASBR上接收本域内和域外传过来的所有VPN路由,然后再把VPN给扩散出去。但是MPLS VPN的特性结构中要求,只有一个PE上有VPN匹配某条VPN路由时,这条VPN路由才会被保存下来。因此对于上述ASBR上需要保存VPN路由,这要求本地要配置它匹配的VPN实例。当然,也可以通过配置undo policy vpn-target来实现不配置vpn实例传递路由的功能。
l 由于这种方案需要在ASBR上保存所有的VPN路由,因此对路由器提出了很高的要求,使ASBR更容易成为故障点。不过只要VPN的路由数量不是很多,这种方案不失为一种配置简单且实用的方案,特别适合网络规模较小的企业网用户。
3.2.3 多跳MP-EBGP的组网应用
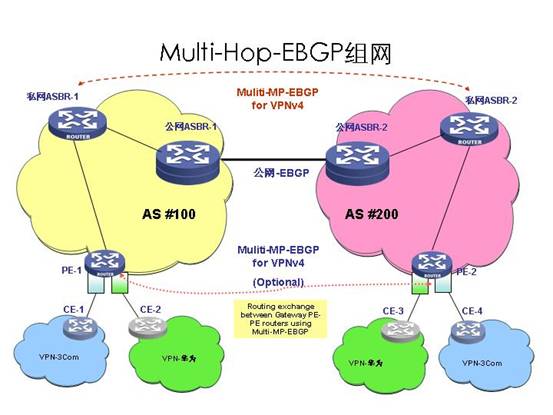
此方案本身也分为3种方式:
l 模式1(不改变PE下一跳方式):本AS内PE将本地的loopback接口要泄漏到对方AS中,因为私网下一跳并没有改变,所以公网ASBR要为此loopback主机路由分配标签(BGP标签),这样对方AS中会有大量的本AS中的主机路由,单纯的PE-PE的配置会非常繁琐,可以在本AS内选用私网ASBR的组网方式,减少了配置量。同时最内层VPN路由的私网标签没有更改。但本AS内各设备的loopback 主机路由还会泄漏到对方AS中,在运营商组网中基本是不允许的,企业网无此限制。
l 模式2(本AS内私网ASBR改变PE下一跳):由本AS内ASBR充当一个管理者,它将本AS内PE的VPN路由的下一跳都更改为自己,然后与对方AS中相同地位的私网ASBR建立针对VPN业务的EBGP邻居,这样ASBR只需要将私网ASBR的loopback主机路由发送到对方AS中,同时减少了配置量,注意对方AS中的PE查看到的本方AS中VPN路由的下一跳为本方的私网ASBR,也就是说最内层VPN路由的私网标签更改过一次(知道在哪儿吗?) 。这种组网比较符合运营商组网。
l 模式3(本AS和对方AS中的私网ASBR都更改PE下一跳):由本AS内私网ASBR和对方AS内的私网ASBR充当自己域内的管理者,抽象来看,就是两个私网ASBR之间建立的EBGP邻居,采用标准的EBGP发送路由方式,本方修改下一跳方式,这样公网ASBR也只需要将私网ASBR的loopback主机路由发送到对方AS中,但最内层VPN路由的私网标签更改过2次(哪两次?)。这种组网也比较符合运营商组网。
方案三的总体特点:
l 利用了BGP的一个新特性(RFC 3107),这个特性可以让BGP在传递公网路由的时候携带标签。
l BGP本身是靠TCP建立连接,所以只要两个端点可达到,就可以建立BGP的邻居,从而完成VPN路由的交换。第三种方式实际上就是靠两个PE设备之间建立多跳的MEBGP邻居来完成VPN路由交互的。
l MULTIHOP-EBGP的跨域方案应该说对于运营商是最理想的,因为它符合MPLS VPN的体系结构的一些要求。比如VPN的路由信息只出现在PE设备上,而P路由器只负责报文的转发。这样就使中间域的设备可以不支持MPLS VPN业务,仅充当一个普通的支持MPLS转发的ASBR路由器,可以同时支持跨域的需求和普通的IP业务,尤其是在跨越多个域时优势更加明显。这个方案更适合支持MPLS VPN的负载分担等功能,也没有可能会成为性能瓶颈的点。不过由于这种解决方案中需要对普通的BGP做扩展,且隧道的生成也是有别于普通的MPLS VPN结构,因此维护和理解起来难度比较大,不适合用于企业网的环境。