文/史计达
队列调度机制在QoS技术体系中属于拥塞管理的范畴。虽然企业和运营商想尽一切办法
去扩展自己的链路带宽,但是现实网络上各种应用对带宽的消耗速度远远超出企业和运营商带宽扩充能力,也就是说网络的拥塞是无法避免的,这也决定了拥塞管理这一技术的重要性。拥塞管理是指网络发生拥塞时,如何进行管理和控制,处理的方法是使用合适的队列技术来确保关键业务的优先保障。在出接口发生拥塞时,通过适当的队列调度机制,可以优先保证某种类型的报文的QoS参数,例如带宽、时延、抖动等。我们这里所说的队列是指出队列,其实就是指向指定缓存的一系列指针,其作用是在接口有能力发送报文之前先将报文在缓存中保留下来,直到接口可以继续发送报文,所以队列调度机制都是在出端口发生拥塞情况下产生作用,另外一个主要作用就是将报文重新排序(FIFO除外)。
队列是一个比较容易理解的概念,我们在日常生活中也用到类似技术。例如我们去电影院买票的时候,大家排成几队顺序买票,排在前面的先拿到票(FIFO);有时突然冲出一个人跑到队伍的最前面拿出VIP证件马上就拿到了票(PQ),这类人属于特权阶级需要优先处理,后面的人只能等这类人买完票才能继续排队买票。
FIFO是队列机制中最简单的,每个接口上只有一个FIFO队列,表面上看FIFO队列并没有提供什么QoS保证,甚至很多人认为FIFO严格意义上不算做一种队列技术,实则不然,FIFO是其它队列的基础,FIFO也会影响到衡量QoS的关键指标:报文的丢弃、延时、抖动。既然只有一个队列,自然不需要考虑如何对报文进行复杂的流量分类,也不用考虑下一个报文怎么拿、拿多少的问题,即FIFO无需流分类、调度机制,而且因为按顺序取报文,FIFO无需对报文重新排序。简化了这些实现其实也就提高了对报文时延的保证。
FIFO关心的就是队列长度问题,队列长度会影响到时延、抖动、丢包率。因为队列长度是有限的,有可能被填满,这就涉及到该机制的丢弃原则,FIFO使用Tail Drop机制。如果定义了较长的队列长度,那么队列不容易填满,被丢弃的报文也就少了,但是队列长度太长了会出现时延的问题,一般情况下时延的增加会导致抖动也增加;如果定义了较短的队列,时延的问题可以得到解决,但是发生Tail Drop的报文就变多了。类似的问题其它排队方法也存在。
Tail Drop机制简单的说就是如果该队列如果已经满了,那么后续进入的报文被丢弃,而没有什么机制来保证后续的报文可以挤掉已经在队列内的报文。
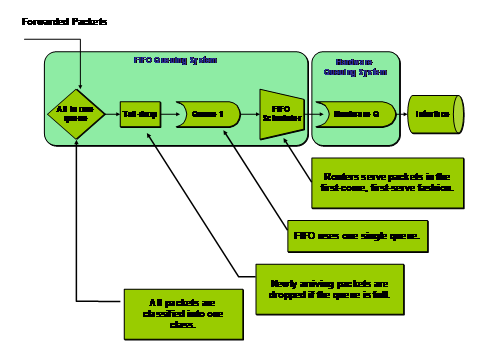
图1 FIFO流程图
阶级社会将不同的人划入到不同的阶层,不同的阶层享受的关照度不同,如果把FIFO比作原始社会的话,那么PQ就进入了封建社会了。
在报文到达接口后,首先对报文进行分类,然后按照报文所属类别让报文进入所属队列尾部,在报文发送时,按照优先级,总是在所有优先级较高队列中报文发送完毕后,再发送低优先级队列中报文,这样,在每次发送报文时,总是将优先级高的报文先发出去,保证了属于较高优先级队列报文有较低时延,所以PQ的优缺点是很明显的:优点是可以保证高优先级队列的报文可以得到较大带宽、较低的时延、较小的抖动;缺点是低优先级队列的报文不能得到及时的调度,甚至得不到调度,即会出现“饿死”现象。
PQ具有如下特征:
(1) 报文丢弃策略采用Tail Drop机制;
(2) 每个队列内部使用FIFO逻辑;
(3) 当从队列调度报文时,先从高优先级的队列调度报文
从上面可以看出,PQ一般的应用场合是保证某类流量尽可能得到最好的服务,而不管其它流量的“死活”。
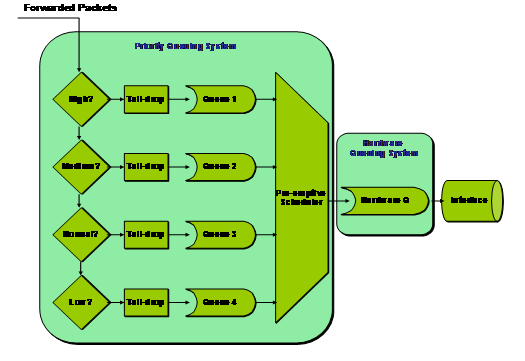
图2 PQ流程图
CQ可以说是对PQ的一种改进,解决了PQ“饿死”的重大缺点,能够确保使所有的队列都得到服务。CQ可以把报文分类,然后按照类别将报文分配到CQ的一个队列中去,而对于每个队列,也可以规定队列中报文所占接口的带宽比例,这样,可以让不同业务的报文获得合理的带宽,从而既保证关键业务能获得较多的带宽,又不至于使非关键业务得不到带宽。
CQ有0-16个队列,其中0队列是优先级队列,只有0队列的报文处理完才会去处理1-16队列,所以0队列一般用做系统队列。
CQ采用Round Robin调度方式,从队列1开始,从每个队列取出指定数目的报文,直到
报文数目满足或者超出设置的范围,当从该队列取出了足够的报文或者队列中没有报文的话,开始对下一个队列进行类似的操作。CQ不会配置确切的链路带宽比例,而是配置字节数目,可以根据配置的每个队列应取得的字节数目计算出每个队列占用的链路带宽,公式为:该队列应取得的字节数目/所有队列应取得的字节数目=该队列占用的链路带宽。如果一段时间内某个队列为空,剩余的队列按照比例分配该空队列所占用的带宽。举个例子来说:现在配置了5个队列,每次取的字节数分别为5000、5000、10000、10000、20000,如果5个队列都有充足的报文需要发送,那么每个队列分配的带宽比例为10%、10%、20%、20%、40%;假设队列4有一段时间内没有报文发送,即队列为空,那么剩余的4个队列把这20%的带宽按照1:1:2:4的比例进行分配,所以在这段时间内这四个队列实际分配的带宽为12.5%、12.5%、25%、50%。
CQ不能将报文进行分片,例如要从队列1拿出1500字节的报文,可能会出现如下情况:
前面拿了1499bytes,还需要拿1byte,但是紧接着的一个报文大小是1500bytes,那么实际上从该队列拿出了1499+1500=2999bytes了,所以从局部来看的话,调度的比例和预期设置的结果有出入。
CQ有如下特点:
(1) Tail Drop是唯一的丢弃机制;
(2) 最大16个队列(因为0队列用做系统队列,这里不计算在内);
(3) 队列内部使用FIFO逻辑;
(4) 在对各队列进行调度时,使用Round-Robin对各队列按字节数调度。
CQ可以应用在对抖动要求不严格同时能够根据需要对不同分类的流量保留指定链路带宽的情况。CQ没有像PQ一样对某类流量提供低时延的服务,但是它可以保证在发生拥塞时1-16队列能够分配到指定额度的带宽。
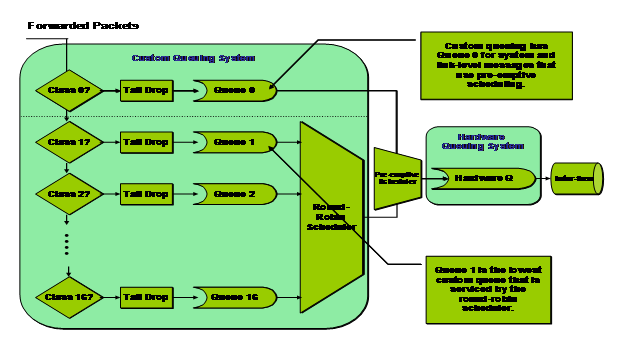
图3 CQ流程图
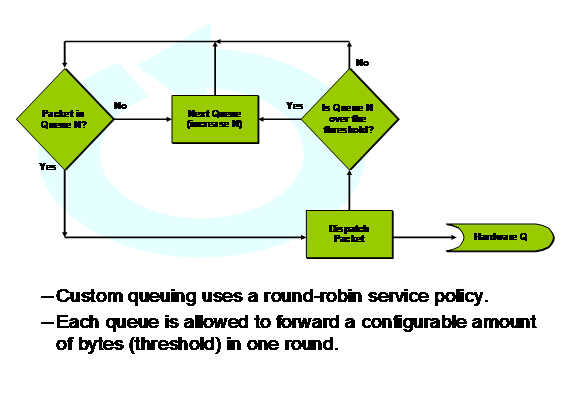
图4 CQ的RR调度流程图
WFQ是根据流对报文进行动态分类,对于IP网络,五元组(源IP地址、目的IP地址、源端口号、目的端口号、协议号)和IP优先级或者DSCP相同的报文属于同一个流。在接入层的网络中,通常使用IP优先级和五元组配合进行流分类;在汇聚层网络中通常使用DSCP值和五元组配合进行流分类,具有相同特性的报文属于同一个流,使用Hash算法映射到不同的队列中;另外的一个区别就是如果使用WFQ,那么low-volume(字节数小的报文)、higher-precedence(优先级高的报文)的流会比large-volume、lower-precedence的流更先处理。因为WFQ是基于流的,每个流使用不同的队列,这就要求WFQ能够支持很大数目的队列――WFQ最大可以在每个接口支持到4096个队列。
WFQ与CQ主要区别如下:
(1) CQ可以自定义ACL规则来对报文进行分类,而WFQ只能根据元组对报文进行动态分类
(2) WFQ和CQ的队列调度方式不一样,CQ的调度方式是RR,而WFQ的调度机制是WFQ调度机制
(3) WFQ和CQ的报文丢弃机制不一样:CQ使用Tail Drop机制,WFQ使用WFQ丢弃机制,该机制是对Tail Drop的一种改进
要想理解WFQ,必须了解这个机制出现的目的是什么,即使用WFQ是为了达到什么目
的?WFQ调度主要是为了两个主要的目的,一个是在各个流之间提供公平的调度即WFQ名字中的F(fairness)的含义,另外一个就是保证高IP precedence的流能够得到更多带宽即WFQ名字中的W(weighted)的含义。
为了提供各个流之间的公平调度,WFQ给每个流分配的带宽是相同的。例如一个接口
有10条流,该接口带宽为128Kbps,那么每个流得到的带宽为128/10=12.8Kbps。从某种意义上讲,有些类似于时分复用机制(TDM)。WFQ允许其它流使用某条流的剩余带宽,例如接口带宽为128kbps,共10条流,则每条流分配的带宽为12.8kbps,可能实际上某条流例如流1只有5kbps,而流2有20kbps,那么其它的流就可以分配流1所剩余下的12.8-5=7.8kbps的带宽。
WFQ的加权是根据流中的IP precedence进行的,保证高IP precedence的流分配到更
多的带宽。算法为(IP precedence+1)/Sum(IP precedence+1),例如有四个流,其IP precedence分别为1、2、3、4,那么每个流占用的带宽分别为2/14、3/14、4/14、5/14。
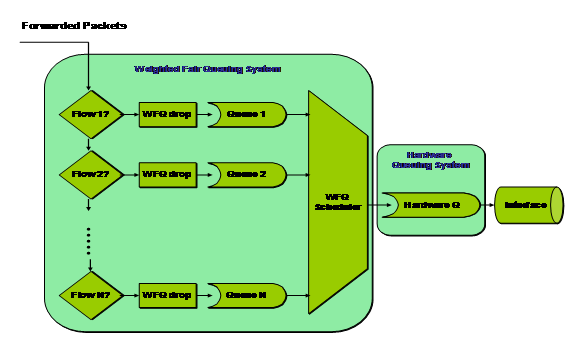
图5 WFQ流程图
要想理解WFQ的报文丢弃机制和队列调度机制,需要理解WFQ中的一个重要概念:序列号SN(不同的文档可能采用不同的参数,不管使用什么参数都应该达到小字节、高IP优先级的流被优先调度),报文在经过流分类后,在决定该报文是入队列还是丢弃之前,都要赋予一个SN。SN的计算公式为SN=Previous_SN+weight*new_packet_length,WFQ进行报文调度时都是先调度SN小的报文,为了保证IP Precedence大的能够获得更多的带宽,从SN的计算公式就可以看出Weight应与Precedence成反比。
其中Previous_SN分为两种情况:
(1) 如果报文进入的队列为非空,使用该队列中最近进入队列报文的SN作为Previous_SN;
(2) 如果报文进入的队列为空,使用发送队列最近发送的报文的SN作为Previous_SN。
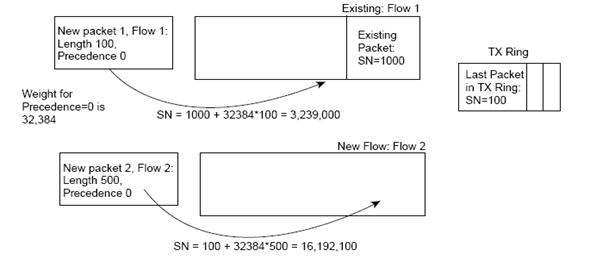
图6 Previous_SN的选择
WFQ在进行报文丢弃和入队列时也是根据SN的大小来进行的:
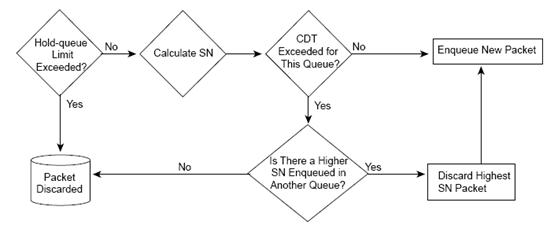
图7 报文丢弃原理
HQL(Hold-queue-Limit):限制了所有队列中能够存放的报文总数目;
CDT(Congestive Discard threshold):限制了每个队列中能够存放的报文数目。
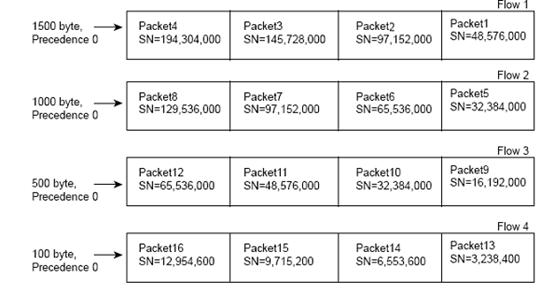
图8 SN的选择
上图中:有四条流,每条流的precedence相同都为0,只是报文的大小不同,Flow1到Flow4的报文长度从大到小,按照SN的计算公式,报文长度小的SN小,所以Flow4中的报文应该被优先调度出去,当然最终的决定因素还是SN的大小,对于SN相同的报文实行顺序调度,如本例所示:Packet5和Packet10的SN相同、Packet1和Packet11的SN相同,按照顺序调度规则,应该是Packet5在Packet10前,Packet1在Packet11前。最终的调度的结果是:13,14,15,16,9,5,10,1,11,6,12,2,7,8,3,4。
WFQ使用WFQ丢弃机制,该机制是对tail drop的一种改进,其中的一个决定因素也是SN,另外WFQ还使用HQL和CDT来决定如何对报文进行丢弃。如果一个新的报文达到时HQL已经到达最大值,该报文直接被丢弃;如果此时HQL没有到达最大值,WFQ将该报文根据WFQ的分类原则进行分类决定进入到哪个队列并计算出SN,剩下的丢弃机制还会由CDT决定,CDT是每个队列自己的丢弃阀值,如果此时CDT没有到达最大值报文直接进入该队列,如果CDT已经达到阀值,则判断其它队列是否有SN比新进入的报文SN大,如果没有直接丢弃新进入的报文,如果其他队列有SN大于当前入队列的报文,WFQ会选择丢弃SN大最大的报文。简单的说就是当某个队列的报文数目已经超过该队列CDT,WFQ可以选择丢弃其它队列中SN最大的报文!其流程图可以参见上面的图8。
将WFQ的特点可以总结为如下特点:
(1) 基于元组对报文进行流分类,不支持用户自定义的分类
(2) WFQ丢弃机制,是对Tail Drop的改进
(3) 队列内部使用FIFO
(4) WFQ调度:优先服务低SN的报文
CBWFQ从名字来看像是CQ和WFQ的混合体。和CQ类似的,CBWFQ可以为每个队列保留最小带宽,使用和CQ类似的报文分类,但是与CQ不同的是,用户可以配置CBWFQ实际占有的流量百分比,而不是字节数;和WFQ相比,CBWFQ可以在一个特定的队列里面使用WFQ机制:CBWFQ有一个特殊的队列,即缺省队列,只有该特殊队列可以采用WFQ机制。
CBWFQ支持两种丢弃机制:Tail Drop和WRED。可以配置任何一个队列的丢弃机制为WRED,但是并不是所有的队列配置WRED丢弃机制都是有益的,WRED可以用在对丢包不是很敏感的数据队列;如果该队列是存放语音、视频报文,这类业务报文对丢包比较敏感就不适合采用WRED了。
CBWFQ有0-64队列,0队列是缺省队列,该队列是自动配置、不可人工干预。可以使用流分类将不同类型的报文映射到1-64队列,可以设置每个队列所占用的带宽比例;如果进入的报文不能匹配任何流分类,进入缺省队列,缺省队列可以使用FIFO或者WFQ机制,而1-64只能使用FIFO机制。为什么只有缺省队列0可以采用WFQ机制?这样有什么好处呢?前面已经提到CBWFQ可以根据分类将报文放入到指定队列,通过配置该队列的带宽比例获取相应的服务,如果在一段时间某个队列不需要该带宽,由其它队列共享;对于那些无法进行分类的报文统统放入到队列0,通过在0队列使用WFQ机制可以使该队列中的所有报文能够得到公平的调度。
CBWFQ的有一个严重的缺点就是没有一个队列可以满足那些对时延有特殊要求的报文,例如语音、视频流,也就是缺乏类似于PQ之类的严格优先级队列。
从名字我们就可以大致知道这个队列的作用,就是为了保证某类报文的低时延,目前的实现方式都是通过严格优先级队列来保证该类报文被优先处理,从而对时延加以保证。实际上LLQ严格意义上并不是一个独立的队列机制,可以认为它是CBWFQ队列机制的一个变种。通过在在CBWFQ队列中加入了一个或者几个优先级队列来实现,以保证这些队列的优先处理,从而保证进入该分类的报文较低的时延;而通过设置带宽阀值,又能防止出现“饿死”现象。
LLQ在调度时一直首先检查低时延队列,从该队列取报文,如果该队列没有报文时才转向其它非低时延队列。LLQ可以设置多个低延时队列,多个低延时队列之间的关系是平等的,采用的FIFO逻辑,用户可以根据需要将不同的业务放入到不同的低延时队列,例如语音流放到一个低延时队列,视频流放到另外一个低延时队列,可以更好的保证两种业务能够同时得到相应的服务。低延时队列和非低延时队列之间的关系类似PQ,既然类似PQ就不可避免的出现“饿死”现象。LLQ通过设置低时延队列的带宽值来防止“饿死”现象出现。
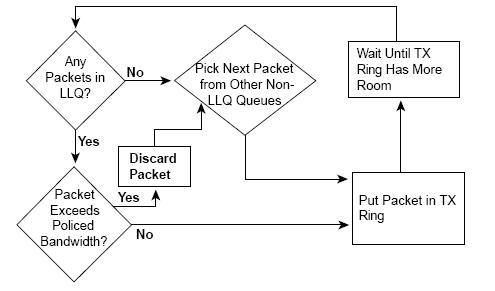
图9 LLQ原理图
从上图中可以看出,为了保护其它非LLQ队列得到调度,LLQ采用丢弃LLQ队列超
过指定带宽的报文的方式来实现该目的,这样的负面影响也是很明显的:语音、视频流量需要进入LLQ队列来保证低时延、低抖动,它们同样对报文丢弃很敏感,这样反而失去了LLQ的本来意义,有点矛盾,唯一的办法就是合理安排好LLQ队列所占用的带宽比例,尽可能的保证该队列的报文不出现丢包。
IP RTP和LLQ类似,但又有一些不同点。它通过在WFQ或者CBWFQ队列中加入严格优先级队列来实现的,它通过区分UDP报文的目的端口号来对VOIP报文进行分类,从中选择出UDP目的端口号在一定范围之内且为偶数的流量。因为IP RTP是严格优先级队列,所以会被最先处理,并且通过一定的策略防止这个严格优先级队列占用太多的带宽,也就是说该严格优先级队列占用的带宽是有额度的,超过限制的流量被丢弃。
通过RTP的实现可以看出,RTP具有如下特点:
(1) 在CBWFQ中增加了一个低时延队列,保证VOIP报文的及时处理;
(2) 限制了优先级队列带宽大小,防止出现“饿死”现象;
(3) 流分类手段贫乏。
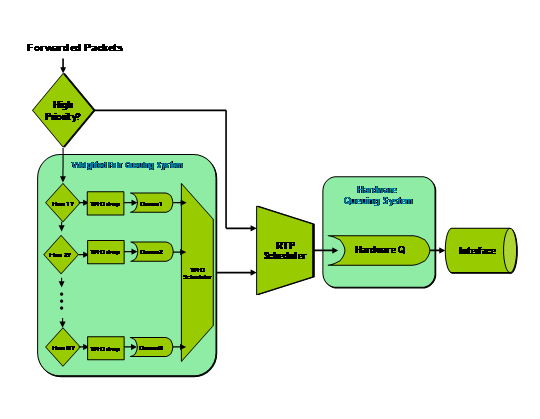
图10 RTP流程图
对于队列机制而言,它的最重要的两个特性就是调度方式和丢弃机制,在学习队列机制时要从这两个特性去考察、对比不同队列机制之间的共同点和不同点,明白不同队列机制不同的应用场合。
队列调度机制 | 调度方式 | 丢弃机制 |
FIFO | 顺序调度 | 尾丢弃 |
PQ | 首先调度高优先级队列 | 尾丢弃 |
CQ | 从每个队列取指定字节的报文,队列之间采用RR机制 | 尾丢弃 |
WFQ | 先调度SN小的报文 | 改进的尾丢弃 |
CBWFQ | 保证每个队列的设定带宽 | 尾丢弃或WRED |
LLQ | 首先服务低时延队列,但是低时延队列有阀值 | 尾丢弃或WRED |
IP RTP priority | 首先服务低时延队列,但是低时延队列有阀值 | 尾丢弃 |
图11 各队列的对比图



 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友