文/程锋章
BGP有三种基本的网络拓扑结构:
u 单口AS (stub AS):一个AS通过单一出口点到达其域外的网络;
u 多归路非过渡AS (Multihomed AS):一个AS有多于一个到达外部网络的出口点但它不允许业务量通过它过渡;
u 过渡AS (transit AS):一个AS有多于一个到达外部网络的出口点并且它允许被其他AS用于过渡业务量;
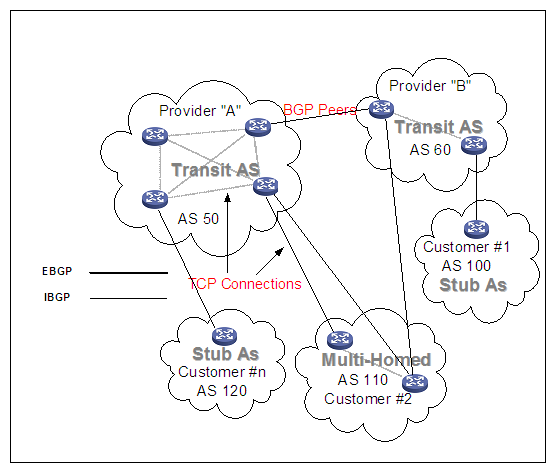
图1 BGP典型拓扑结构
从BGP的观点上来看整个Internet的拓扑就是由一系列单口AS多归路非过渡AS和过渡AS组成的连通图。每个AS用AS号码来识别两个AS之间的连接形成一个路径,BGP保证无循环域间选路路径信息的汇集形成一棵路径树,这棵路径树就是到达特定目的地的路由。
BGP是否很难学无法给出一个确切的说法,但是可以肯定的是学习和使用BGP绝对很过瘾。BGP在路由协议中的地位是非常高的,在核心路由器上应用极多,与之相关的特性如L2vpn、L3vpn以及路由策略等比较多,其主要是用来控制路由的发送和接受,而IGP路由协议皆属于其可控制的对象,同时个人觉得学好BGP也是学好MPLS VPN的重要基础之一。
对于BGP的学习首先可以参考以前比较好的经验总结,加强对BGP设计原理的了解;而《TCP/IP routing Ⅱ》,对BGP各种报文、属性以及相关应用场景做了非常详尽的阐述,也值得刚开始好好学习。
当然一门协议的掌握还是需要大量的积累和实践,对于相关RFC的了解也必不可少,BGP相关RFC如下:
l RFC 4808,Mar 2007 Key Change Strategies for TCP-MD5
l RFC 4797,Jan 2007 Use of Provider Edge to Provider Edge (PE-PE) Generic Routing Encapsulation (GRE) or IP in BGP/MPLS IP Virtual Private Networks
l RFC 4781,Jan 2007 Graceful Restart Mechanism for BGP with MPLS
l RFC 4761,Jan 2007 Virtual Private LAN Service (VPLS) Using BGP for Auto-Discovery and Signaling
l RFC 4760,Jan 2007 Multiprotocol Extensions for BGP-4
l RFC 4724,Jan 2007 Graceful Restart Mechanism for BGP
l RFC 4684,Nov 2006 Constrained Route Distribution for Border Gateway Protocol/Multiprotocol Label Switching (BGP/MPLS) Internet Protocol (IP) Virtual Private Networks (VPNs)
l RFC 4698,Oct 2006 IRIS: An Address Registry (areg) Type for the Internet Registry Information Service
l RFC 4659,Sep 2006 BGP-MPLS IP Virtual Private Network (VPN) Extension for IPv6 VPN
l RFC 4632,Aug 2006 Classless Inter-domain Routing (CIDR): The Internet Address Assignment and Aggregation Plan
l RFC 4486,Apr 2006 Subcodes for BGP Cease Notification Message
l RFC 4456,Apr 2006 BGP Route Reflection: An Alternative to Full Mesh Internal BGP (IBGP)
l RFC 4451,Mar 2006 BGP MULTI_EXIT_DISC (MED) Considerations
l RFC 4384,Feb 2006 BGP Communities for Data Collection
l RFC 4382,Feb 2006 MPLS/BGP Layer 3 Virtual Private Network (VPN) Management Information Base
l RFC 4381,Feb 2006 Analysis of the Security of BGP/MPLS IP Virtual Private Networks (VPNs)
l RFC 4365,Feb 2006 Applicability Statement for BGP/MPLS IP Virtual Private Networks (VPNs)
l RFC 4364,Feb 2006 BGP/MPLS IP Virtual Private Networks (VPNs)
l RFC 4360,Feb 2006 BGP Extended Communities Attribute
l RFC 4278,Jan 2006 Standards Maturity Variance Regarding the TCP MD5 Signature Option (RFC 2385) and the BGP-4 Specification
l RFC 4277,Jan 2006 Experience with the BGP-4 Protocol
l RFC 4276,Jan 2006 BGP-4 Implementation Report
l RFC 4275,Jan 2006 BGP-4 MIB Implementation Survey
l RFC 4274,Jan 2006 BGP-4 Protocol Analysis
l RFC 4273,Jan 2006 Definitions of Managed Objects for BGP-4,This document obsoletes RFC 1269 and RFC 1657.
l RFC 4272,Jan 2006 BGP Security Vulnerabilities Analysis
l RFC 4271,Jan 2006 A Border Gateway Protocol 4 (BGP-4).This document obsoletes RFC 1771.(最新的BGP RFC,废除了1771)
l RFC 4098,Jun 2005 Terminology for Benchmarking BGP Device Convergence in the Control Plane
l RFC 3913,Sep 2004 Border Gateway Multicast Protocol (BGMP): Protocol Specification
l RFC 3882,Sep 2004 Configuring BGP to Block Denial-of-Service Attacks
l RFC 3779,Jun 2004 X.509 Extensions for IP Addresses and AS Identifiers
l RFC 3765,Apr 2004 NOPEER Community for Border Gateway Protocol (BGP) Route Scope Control
l RFC 3562,Jul 2003 Key Management Considerations for the TCP MD5 Signature Option
l RFC 3392,Nov 2002 Capabilities Advertisement with BGP-4.This document obsoletes RFC-2842(废除了2842).
l RFC 3345,Aug 2002 Border Gateway Protocol (BGP) Persistent Route Oscillation Condition
l RFC 3221,Dec 2001 Commentary on Inter-Domain Routing in the Internet
l RFC 3107,May 2001 Carrying Label Information in BGP-4(BGP开始支持标签)
l RFC 3065,Feb 2001 Autonomous System Confederations for BGP
l RFC 2918, Sep 2000 Route Refresh Capability for BGP-4(BGP支持路由刷新能力)
l RFC 2545,Mar 1999 Use of BGP-4 Multiprotocol Extensions for IPv6 Inter-Domain Routing
l RFC 2519,Feb 1999 A Framework for Inter-Domain Route Aggregation
l RFC 2439, Nov 1998 BGP Route Flap Damping
l RFC 2385,Aug 1998 Protection of BGP Sessions via the TCP MD5 Signature Option
l RFC 2270,Jan 1998 Using a Dedicated AS for Sites Homed to a Single Provider
l RFC 1998,Aug 1996 An Application of the BGP Community Attribute in Multi-home Routing
l RFC 1997,Aug 1996 BGP Communities Attribute
l RFC 1930,Mar 1996 Guidelines for creation, selection, and registration of an Autonomous System (AS)
l RFC 1774,Mar 1995 BGP-4 Protocol Analysis
l RFC 1773,Mar 1995 Experience with the BGP-4 protocol
l RFC 1772,Mar 1995 Application of the Border Gateway Protocol in the Internet
l RFC 1771, Mar 1995 A Border Gateway Protocol 4 (BGP-4)
l RFC 1745,Dec 1994 BGP4/IDRP for IP---OSPF Interaction
全局Router ID可以在全局模式下通过配置命令router id来配置,如果没有通过命令指定,系统会从当前接口的IP地址中自动选取一个作为路由器的ID号。其选择顺序是:优先从Loopback地址中选择最大的IP地址作为路由器的ID号,如果没有配置Loopback接口,则选取接口中最大的IP地址作为路由器的ID号。只有在路由器的Router ID所在接口被删除或去除手工配置的Router ID的情况下才会重新选择路由器的Router ID。为了增加网络的可靠性,建议将Router ID手工配置为Loopback接口的IP地址。
BGP的Router ID可以在启动BGP进程后通过BGP全局模式下的配置命令router-id来指定,若未配置则采用全局Router ID值。通过BGP的配置命令修改RouterID会导致已经建立的BGP peer会全部重启,如:
bgp 100
router-id 1.1.1.1
H3C COMWAREV5平台支持手工配置。
BGP路由往往很多,但是并不是都会进行转发处理,大概有如下几条规则:
1) 多条路径时,BGP Speaker只选最优的给自己使用,当然也可以设置负载分担,负载分担请见本文ECMP章节;
2) BGP Speaker只把自己使用的路由通告给相邻体,也就是说本地BGP路由表里面不是最优的路由不会再进行转发处理等操作;
3) BGP Speaker从EBGP获得的路由会向它所有BGP相邻体通告(包括EBGP和IBGP),当然路由不会再从原路发送回去;
4) BGP Speaker从IBGP获得的路由不向它的IBGP相邻体通告(反射和联盟可以解决这个问题);
5) BGP Speaker从IBGP获得的路由默认会向它所有EBGP相邻体通告;若配置了同步,是否通告给它的EBGP相邻体要依IGP和BGP同步的情况来决定;
BGP不同于其他IGP协议,其路由都包含了丰富的路由属性,并通过路由属性来对路由进行过滤,其中一个属性为AS_PATH,该属性为该路由经过的所有AS的序列,这样对于收到的路由,通过对AS_PATH进行检查,如果发现自身的AS号已经出现在AS_PATH属性中,那么就表示自身发布的路由又重新回到自己所处的AS中,已经出现了路由环路,这时就会丢弃接收到的路由,从而避免继续对外发布路由,导致环路产生。
当然还可以参考上面的BGP使用原则,比如BGP从IBGP收到的路由不继续往IBGP邻居发送,这也是协议上避免环路的一种方法(反射路由的处理类似,请参看后续章节)。
正常情况下BGP会丢弃AS_PATH中包含自身AS号的路由。对于特定情况下导致的AS号重复的合理环境,可以通过如下命令来进行控制“peer { group-name | peer-ipv4-address } allow-as-loop [ number ]”,其中number取值范围为<1-10>,默认值为1,即允许接收路由的AS_PATH中包含一个自身AS号。当然,在向EBGP邻居发布时,也还要在AS_PATH最后再加上自身的AS号。
有不少原因,最常见原因如下:
1) 两边BGP peer地址不可达,一般是底层原因或者缺少可达的路由,可以使用扩展的ping命令检查TCP连接是否正常,由于一台路由器可能有多个接口能够到达对端,应使用ping -a ip-address命令指定发送ping包的源IP地址。
2) 对等体IP地址和AS配置错误,常为大意所致;
3) OPEN报文协商失败,OPEN报文需要协商BGP版本、Holdtime、RouterID以及可选项参数(包括各种能力参数)等;H3C COMWAREV5平台实现当接受到不支持的能力参数时候直接进行忽略而不影响建立连接;
4) BGP的MD5验证配置错误;
5) BGP的RouterID冲突;
6) 联盟与非联盟之间的BGP连接配置错误;
7) 错误报文导致连接中断,比较少见的如BGP的Marker值出现错误;
8) 还有一些比较特殊的情况,请参考下文;
有不少方法,最常见方法如下:
1) 首先打开调试开关deb bgp X.X.X.X all开关,确认状态机在哪一步出现错误;
2) 如果BGP状态始终在active状态徘徊,表示TCP建立不起来,首先排除底层不通和路由不可达的情况;
3) 如果BGP状态始终在active状态徘徊,其次排除BGP的MD5验证问题;
4) 如果BGP状态始终在active状态徘徊,最后特殊配置问题,比如IBGP的connect-interface或者EBGP peer的ebgp-max-hop等,见下文;
5) 如果是Open报文协商错误,通过调试开关,H3C COMWAREV5平台能够很方便的查看到具体的错误类别和信息,然后根据错误提示采取具体措施;
在实际应用过程中,H3C设备在与友商设备进行BGP能力协商过程中遇到无法识别和支持的能力参数,比如有的是最新RFC规定而我司没有实现的,有的是友商自定义的能力,在类似情况处理过程中会忽略无法识别的能力,打出信息并继续建立邻居。
在RFC 2842中BGP协议要求BGP speaker在收到的OPEN报文中带有一个或多个不认识的可选项参数时,它会中断BGP的会话连接,然后对方会继续进行BGP连接,此时不带上上述不认识的选项参数。不过此RFC已经被RFC3392(Capabilities Advertisement with BGP-4)所废除。
根据RFC3392的要求,当一个支持能力通告的BGP speaker向其BGP peer发送OPEN消息时,其消息可以包含称之为能力的选项参数,该参数列出它所支持的所有能力:
1) BGP speaker通过检查从其BGP对等体收到的OPEN消息中的能力列表来确定对方所支持的所有能力;
2) 如果BGP speaker支持上述能力列表中的一种能力后直接使用该能力并保持BGP连接,这样不用发送NOTIFICATION并再次进行协商;
3) 如果BGP speaker在收到对方对于本端发出的OPEN消息的响应是NOTIFICATION 并且其Error Subcode为Unsupported Optional Parameter,此时认为对方不支持先前的能力通告。本端将试图重新和对方建立连接,此时本端发送的OPEN消息中将不再携带对端不支持的能力选项参数Capabilities Optional Parameter。
4) 如果一个BGP speaker支持某一特定能力发现对方不支持该能力,该BGP speaker可以向对方发送NOTIFICATION消息并终止该会话;此时的ErrorSubcode设定为Unsupported Capability,该NOTIFICATION消息将在Data域中包含引起会话中断的能力。而是否发送消息并中断会话,取决于本端BGP speaker,并且一旦中断将不再重新自动连接。
BGP的能力参数类型有两种,即多协议能力和路由刷新能力;针对地址族的定义就比较多了,不同厂商实现也可能不一样。比如根据最新RFC4761,针对VPLS的能力已经定义为25/65(L2vpn也是25/65)。具体情况见表格:
| CODE | AFI | SAFI |
IPv4 Unicast | Multiprotocol(1) | 1 | 1 |
IPv4 Multicast | Multiprotocol(1) | 1 | 2 |
IPv4 VPNV4 | Multiprotocol(1) | 1 | 128 |
Label IPv4 | Multiprotocol(1) | 1 | 4 |
MVPN | Multiprotocol(1) | 1 | 66 |
L2vpn | Multiprotocol(1) | 196 | 128 |
Ipv6 Unicast | Multiprotocol(1) | 2 | 1 |
IPv6 Multicast | Multiprotocol(1) | 2 | 2 |
IPv6 VPNv4 | Multiprotocol(1) | 2 | 128 |
Label IPv6 | Multiprotocol(1) | 2 | 4 |
VPLS(RFC4761) | Multiprotocol(1) | 25 | 65 |
Refresh | Route Refresh(2) |
|
|
GR | Graceful Restart(64) |
|
|
4-AS | 4-AS(65) |
|
|
Dynamic Capability | Dynamic Capability(67) |
|
|
当排除底层原因后,发现IBGP PEER使用loopback口建立却无法建立。这是因为BGP连接建立首先要建立起两个peer之间的TCP连接,而TCP连接的源地址缺省是路由器相应的出接口的IP地址,所以必须要指定TCP连接的源地址为相应的loopback接口地址,连接才能建立起来,peer X.X.X.X connect-interface命令的功能就是用于指定BGP会话建立TCP连接使用的接口。
很简单,上面的例子是IBGP邻居关系的建立,如果使用Loopback口建立的是EBGP连接,即使是两个直连接口也需要配置ebgp-max-hop,因为两个loopback口不是直连接口。
一般情况下不推荐使用loopback建立EBGP邻居,而一般是使用物理接口地址建立,比如在L3vpn的各种跨域环境中。
如果是EBGP邻居,双方路由可达,且EBGP连接在物理上不是直连的,请检查是否配置了peer的ebgp-max-hop。默认情况下,EBGP邻居不配置这条命令,如果不是直连,必须配置peer X.X.X.X. ebgp-max-hop,该命令的默认值是64。
有不少原因,最常见原因如下:
1) BGP连接建立好后,在协商后的holdtime时间内收不到keepalive报文,导致错误代码为4/0的错误;
2) 收到非法的Update报文导致BGP为了安全考虑自动中断连接,并打印错误信息;
3) MTU问题,路由器会因为一些转发芯片限制或者人为的MTU设置,导致经过多次封装后的BGP报文超过mtu而被丢弃;
4) MTU和QoS设置不当可能导致大的Update报文被丢弃,由于TCP的重传机制,当发送多个大的Update报文时,可能产生大量等待重传的Update报文,从而抑制了keepalive报文的正常发送,当连续收不到keepalive报文时,BGP认为邻居已经Down。
5) 网络拥塞问题:网络拥塞可能导致Keepalive报文收发失常,邻居状态不断改变;另外,如果到达邻居的路由是通过IGP(如OSPF)发现的,网络拥塞可能导致该路由丢失,从而使邻居间的连接中断。
6) 设置原因,导致TCP179端口号不可用;
当然了,BGP所支持的操作非常多,还有很多主动的原因导致BGP会话重新启动:
1) 对端关闭会话,比如对peer配置ignore命令;
2) 如果配置了路由数目限制(peer X.X.X.X route-limit),超过指定数目后也会down掉;不同机型其最大值也不一样。
3) 远端AS改变;
4) 修改路由反射器客户机配置;
5) 修改对等体/组的某些策略或者能力;
6) 配置和反配置BGP的Router ID;
7) 由联盟改为非联盟,或反之;confederation nonstandard也可导致;
8) 无法识别对端发送的BGP报文或者接受到错误的报文。
9) 路由更新报文中的必遵属性缺失。
network命令是BGP各个视图下很强大的路由引入命令,能过将各种IGP有效路由、静态路由、直连路由等引入BGP中发布出去。比如本地存在直连路由或者IGP协议路由172.16.1.0/24,BGP视图下使用network 172.16.1.0命令,目的是准备把这条路由传递到BGP路由表中,但是查看本地BGP路由表里面没有这条路由。
使用BGP的network命令发布路由,前缀和掩码必须完全匹配才能正常发布。172.16.0.0是一个B类网段地址,如果没有mask参数的话,缺省使用16位自然掩码,而上述路由的掩码是24位,所以必须在mask参数中配置24位地址掩码才能正常发布路由。
BGP配置模式下的network命令可以带mask参数,也可以不带。不带mask参数的情况下缺省使用路由的自然掩码。在全局路由表中必须具有前缀和掩码都相同的路由,才能正常发布。
Peer ignore命令用来人为地停止指定对等体/对等体组的激活会话,并且清除所有相关路由信息,禁止与指定对等体/对等体组建立会话,BGP邻居将一直抑制在idle的状态,会话一直处于无法建立的状态。如果该命令用来对于一个对等体组,这就意味着大量与对端的会话突然终止。缺省情况下,允许与BGP对等体/对等体组建立会话。在配置peer ignore命令之后,查看peer状态如下:
<H3C>display bgp peer
BGP local router ID : 19.19.19.19
Local AS number : 100
Total number of peers : 1 Peers in established state : 0
4.4.4.4 4 100 0 0 0 0 02:35:59 Idle(Admin)
参看peer public-as-only命令用来配置发送BGP更新报文时不携带私有自治系统号。举个例子,使用策略给发送路由增加属性,并针对peer使能该功能:
route-policy 1 permit node 0
apply as-path 65535 65534 1000 65532 65531 65530 65530 65529
查看对端路由表发现:
[H3C]display bgp routing-table 60.1.1.0
BGP routing table entry information of 60.1.1.0/24:
From : 66.1.1.1 (2.2.2.2)
Original nexthop: 66.1.1.1
AS-path : 200 65535 65534 1000 65532 65531 65530 65530 65529
Origin : igp
Attribute value : MED 0, pref-val 0, pre 255
State : valid, external,
Not advertised to any peers yet
可以看到私有的AS号一个都没有去掉,为什么了?H3C COMWAREV5平台目前实现的规格如此,只要有公有as号就不进行私有as的删除。如果在策略里面去1000,那么5040收到的路由as-path只有200。
BGP可以通过peer default-route-advertise和default-route import来控制缺省路由发布。Peer default-route-advertise不需要本地存在缺省路由而直接向peer发布缺省路由,而default-route import仅仅表示允许引入本地缺省路由,意思是必须通过import方式引入存在本地路由表里面的IGP默认路由,然后再配置default-route import才能使默认路由正确发布。
在BGP中,向IBGP和EBGP邻居发送路由时,下一跳的处理是不同的。向EBGP邻居(即在AS间传播)发送路由时,next-hop均改为该路由器的出口IP地址(当下一跳修改前后的地址符合第三方下一跳时,不做修改);向IBGP邻居(即在AS内传播)发送路由时,next-hop是不变的。
由于BGP向其他IBGP邻居转发来自EBGP路由时不修改下一跳,这样的话若IBGP邻居所处的设备没有到该下一跳地址的路由,会导致该IBGP收到这条转发自IBGP邻居的EBGP邻居的路由后下一跳不可达,导致路由失效。
解决方案有多种:可以配置next-hop-local,这样收到EBGP路由再往IBGP邻居发送的时候会强制更改下一跳为自己的出接口地址;自治域内所有的设备都配置IBGP邻居且要全链接,通过bgp把下一跳也学过去;通过IGP协议来保证自治域内的所有设备能够知道所有部的接口地址。
假设一个这样的场景,三台AS号不一致的MSR之间分别建立了EBGP邻居关系,其中RTC同时收到RTA和RTB发来的因特网路由。根据RTC的要求,RTA将自己发送给RTC的路由设置MED值为50,而RTB将自己发送给RTC的MED设置为100。RTC希望选择MED值小的路由作为最佳路由,从而对相同目的地来说,把通过RTA的链路作为主链路,而把通过RTB的链路作为备份链路。当时在RTC上面没有把RTA发送过来的路由选为最优,为什么?
BGP在路由优选过程中考虑若干因素,包括本地优先级、AS路径长度、起点类型、MED值等。在前几项都相同的情况下,应选择MED值小的路由作为最佳路由。需要注意的是,MED值默认只在同一个AS传来的路由之间才具备可比性。为了能够在不同AS传来的相同路由之间比较MED值,从而选择MED小的路由作为最佳路由,需要在BGP或者BGP VPN视图下配置命令compare-different-as-med。
在RFC4577(OSPF as the Provider/Customer Edge Protocol for BGP/MPLS IP Virtual Private Networks)中有如下描述:
MED (Multi_EXIT_DISC attribute). By default, this SHOULD be set to the value of the OSPF distance associated with the route, plus 1。即ospf路由被引入到BGP中后MED值需要加1。
因为在PE上引入到BGP中再发布到对端PE上OSPF还原后就丢失了原来生成者的信息,这条路由的原来生成者通过其他途径再收到这这条被还原的路由后,如果进行了计算就会导致环路。MED加1,被还原的路由cost会比原路由cost大,能够在某种程度上避免环路。
命令行vpn-instance-capability simple的作用并不是使能vpn能力,而是使能了多实例CE的能力;同时该能力使MCE不去检查DN位是否已经被置位(当DN位被置位时说明这条LSA由PE发给CE,值得注意的是DN位只存在于3类LSA)。
比如不配置vpn-instance-capability时候,引入到BGP多实例进程中的路由会携带下面类似属性Ext-Community :<OSPF Domain Id: 0.0.0.0:0>, <OSPF AreaNum: 0.0.0.0 RouteType: 5 Option: 1>, <OSPF Router Id: 10.10.1.1:0:0>,<RT: 1:1>,上述扩展团体属性是bgp携带发给对端PE设备的,用来让对端PE上的OSPF进程还原LSA的依据;此时候设备就作为普通的PE,PE上bgp引入ospf路由时,med的值等于ospf路由的cost加1;
[H3C]display bgp vpn vpn vpn-a routing-table 172.32.0.0
BGP local router ID : 104.104.104.104
Local AS number : 100
Paths: 1 available, 1 best
BGP routing table entry information of 172.32.0.0/16:
Imported route.
From : 0.0.0.0 (0.0.0.0)
Original nexthop: 10.10.1.2
Ext-Community :<OSPF Domain Id: 0.0.0.0:0>, <OSPF AreaNum: 0.0.0.0 RouteType:
5 Option: 1>, <OSPF Router Id: 10.10.1.1:0:0>, <RT: 1:1>
AS-path : (null)
Origin : incomplete
Attribute value : MED 2, pref-val 0, pre 150
State : valid, local, best,
Not advertised to any peers yet
当配置了vpn-instance-capability simple后,本地路由器就不是PE了,而成了MCE,这样所以BGP引入OSPF路由时,本地OSPF就不会组装这些属性值给bgp,只是作为普通的引入,处理,BGP路由只会携带扩展团体属性<RT: 1:1>,而引入的ospf路由的其他扩展团体属性则会丢失;
而这个时候bgp引入ospf路由时,med的值等于ospf路由的cost
[H3C-ospf-1000]
#
ospf 1000 vpn-instance vpn-a
vpn-instance-capability simple
area 0.0.0.0
network 10.10.1.0 0.0.0.255
#
[H3C-ospf-1000]display bgp vpnv4 vpn-instance vpn-a routing-table
Total Number of Routes: 3
BGP Local router ID is 104.104.104.104
Status codes: * - valid, > - best, d - damped,
h - history, i - internal, s - suppressed, S - Stale
Origin : i - IGP, e - EGP, ? - incomplete
Network NextHop MED LocPrf PrefVal Path/Ogn
*> 16.16.16.16/32 0.0.0.0 1 0 ?
*> 50.1.1.0/24 0.0.0.0 1 0 ?
*> 172.32.0.0 0.0.0.0 1 0 ?
[H3C-ospf-1000]display ospf routing
OSPF Process 1000 with Router ID 10.10.1.1 Routing Tables
Routing for Network
Destination Cost Type NextHop AdvRouter Area
10.10.1.0/24 10 Transit 10.10.1.1 16.16.16.16 0.0.0.0
Routing for ASEs
Destination Cost Type Tag NextHop AdvRouter
172.32.0.0/16 1 Type2 1 10.10.1.2 16.16.16.16
50.1.1.0/24 1 Type2 1 10.10.1.2 16.16.16.16
16.16.16.16/32 1 Type2 1 10.10.1.2 16.16.16.16
Total Nets: 4
Intra Area: 1 Inter Area: 0 ASE: 3 NSSA: 0
众所周知,一个路由器只支持一个BGP进程,有着唯一的AS号,但是在某些特殊情况下比如网络迁移更换as号的时候为了保证网络切换的顺利,需要一些特性来支持。
H3C COMWAREV5平台通过fake-as命令为指定PEER设置一个假AS号来实现,该特性只针对EBGP PEER有效。该命令用来支持BGP邻居可以配置不同于当前由使能BGP协议时指定的自治系统号,配置peer { group-name | peer-ipv4-address } fake-as [ number ]命令后,该peer和本地建peer关系时,要用fake-as号来代替本地的实际as号。示例说明一下,本地RTX(本地地址57.0.0.1)的BGP配置如下:
bgp 100
router-id 1.1.1.1
undo synchronization
peer 57.0.0.2 as-number 57
peer 57.0.0.2 fake-as 88
那么RTX在向57.0.0.2建立连接时的本地AS将是88,而不是100。与此同时,RTY(本地地址57.0.0.2)配置peer 57.0.0.1时对应的AS号也应该为88,而不是100。相关BGP配置如下:
bgp 57
peer 57.0.0.1 as-number 88
实际应用中,该命令通常和peer { group-name | peer-ipv4-address } substitute-as 结合使用。
同步的目的是为了防止在某种情况下转发“黑洞”的出现,起用同步功能后BGP Speaker 在接收到IBGP邻居发过来的路由后都会查看该路由是否已经在IGP路由表中,如果IGP路由表中有这条路由,BGP路由表才会将这条路由置为有效;如果IGP路由表中没有该路由则BGP表中的该条路由是无效的。如果关闭同步功能,在收到IBGP邻居发来的路由更新后不检查IGP表是否有该路由,而直接将该路由置为有效,这样的话在以下拓扑中就会出项问题:
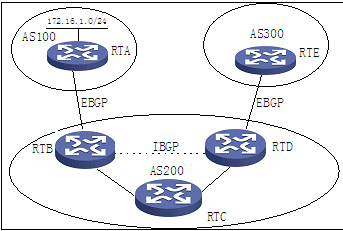
图2 BGP同步原则
在图2中,RTC没有运行BGP,RTD关闭了同步功能。172.16.1.0/24从RTA始发,传播方向为:RTA---------------àRTB---------------àRTD----------------àRTE。RTB、RTD、RTE收到该路由后将其置为有效,这时如果RTE要转发一个目的ip为172.16.1.10的报文的话,将会通过如下步骤转发:
Ø step1:RTE将目的ip为172.16.1.10的报文发给RTD;
Ø step2:RTD接到此报文后将向RTB转发此报文(RTB已使用next-hop-local),但由于RTD与RTB的IBGP连接为逻辑连接,因此去RTB的实际下一跳是RTC,于是又将此报文转发给RTC;
Ø step3:RTC收到此报文后查找路由表,但没有找到匹配项,因为RTC没有运行BGP,不知道172.16.1.10的下一跳,所以此目的ip为172.16.1.10的报文在RTC处就被丢弃了!
RTB、RTC、RTD的IGP路由表中没有172.16.1.0/24的路由,如果开启同步功能的话,RTB向RTD通告该路由时RTD不会将此路由置为有效,RTD也不会向RTE通告该路由,也就避免了上述问题的发生。
在实际环境中AS转接路径中的所有路由器都运行BGP,也就不会出现上述问题,因此可以将同步功能关闭。在具体实现上H3C ComwareV5平台可以支持同步,默认为不同步。
H3C COMWAREV5平台有两种聚合方式,如下:
1) 自动聚合功能:通过summary automatic命令在BGP/BGP VPN视图下配置,默认不使能;自动聚合只聚合通过import-route命令引入的各协议路由(对从邻居收到的BGP路由不生效),且不对缺省路由进行聚合,同时对参与聚合的IGP引入的子网路由会自动进行抑制,从而减少路由选择信息的的数量。这种方法比较死板,而且是按照自然掩码进行聚合,有的时候不能满足需要。
2) 手工聚合:通过aggregate在BGP/BGP VPN视图下配置,该命令携带的参数比较多,而且聚合时候灵活多边,可以与路由策略巧妙结合在一起以达到精确控制的目的。
aggregate在手工聚合时候,如果不设置掩码,会以自然掩码进行聚合,这一点尤其要注意。
根据RFC2858,BGP4+增加2个新属性MP_REACH_NLRI、MP_UNREACH_NLRI用以支持BGP4+,在update报文中只有next-hop、aggregator、NLRI三个字段与IPv4有关;继承了BGP的属性以及各种应用规则。
目前H3C COMWAREV5平台全面支持IPv6功能,增加了对BGP4+的支持,目前重点的特性目前支持BGP4+的团体和反射、单播、组播、路由聚合等功能;
BGP4+是BGP协议的扩展用来支持IPv6地址族,这实际上可以理解为Multi-protocol Extensions for BGP-4(RFC2238)针对IPv6的应用。但是因为下一跳长度等发生变化,单纯的IP地址变化无法满足实际需求。为此,在UPDATE报文中增加了两项optional non-transitive的路由属性对对应地址族下的路由进行控制,分别是Multi-protocol Reachable NLRI - MP_REACH_NLRI (Type Code 14,十六进制:0x0E)和Multi-protocol Unreachable NLRI - MP_UNREACH_NLRI (Type Code 15,十六进制:0x0F)。其中MP_REACH_NLRI用来发布路由,MP_UNREACH_NLRI用来撤销路由。
比如现在有两条缺省路由,一条出接口NULL0,一条是迭代到GE0/1.1上的。BGP路由在迭代时候如何处理?为什么使用display ipv6 relay-tunnel查看迭代计数的时候,只发现基于Null0的统计了迭代次数?
在H3C COMWAREV5平台实际处理中,BGP路由都是迭代到缺省路由上了,而不是直接迭代到GE0/1.1上。只不过有两条等价的缺省路由,所以生成了学过来的每条BGP路由,都多产生一条Derived路由,从而形成等价路由。但实质是迭代到::/上了,所以看到的迭代次数 55::/64仅1次(ipv6 route-static :: 0 55::1 迭代的),::/ 10000次(所有的BGP路由)。目前H3C COMWAREV5平台实现BGP迭代到等价路由可以生成8条等价路由。
H3C COMWAREV5平台的选路规则如下:
Ø 首先丢弃下一跳(Next_Hop)不可达的路由;
Ø 若配置了Preffered-value值,优选值高的;
Ø 优选本地优先级(Local_Pref)最高的路由;
Ø 优选本路由器始发的路由;
Ø 优选AS路径(AS_Path)最短的路由;
Ø 依次选择Origin类型为IGP、EGP、Incomplete的路由;
Ø 优选MED值最低的路由;
Ø 依次选择从EBGP、联盟、IBGP学来的路由;
Ø 优选到下一跳Cost值最小的路由;
Ø 优选Cluster_List长度最短的路由;
Ø 优选Router ID最小的路由器发布的路由。
在路由优选的时候,比较的是AS的长度(即个数),并不比较其内容,但是形成等价路由的时候必须要求其内容也一致。
所以在进行BGP方案部署的时候可以通过使用路由策略,来增加路由的AS-path或者替代AS-path内容等手段来实现指定路由的优选、负载分担等目的。在实际应用中经常可以碰到类似情况。
从EBGP邻居收到的路由不会携带LP(本地优先级,IBGP传递路由会携带此属性),那么路由如何参与决策?
答案是如果显示为空,默认以100参与路由优选!
MED属性仅在相邻的两个AS之间交换,收到此属性的AS一方不会再将其通告给任何其他第三方AS。通过不同的EBGP学到的目的地址相同的多条路由时,在其他条件相同的情况下,优先选择MED值较小者作为最佳路由。
但需要注意的是,BGP缺省只比较来自同一个AS的路由的MED属性值。H3C COMWAREV5平台可以通过compare-different-as-med命令使BGP比较来自不同AS的路由的MED属性值。
除了传统的IGP+LDP方式分发标签外,Label BGP方法也是一种标签分配方式,并且简单和方便操作,在跨域或者C2C环境中经常可以使用到这种典型配置,通过BGP来分配标签,相邻两台路由器配置如下:
bgp 100 ipv4-family vpn-instance vpn200 peer 2.2.2.2 as-number 200 peer 2.2.2.2 route-policy asbr export peer 2.2.2.2 label-route-capability | bgp 200 undo synchronization peer 2.2.2.1 as-number 100 peer 2.2.2.1 route-policy RT2 export peer 2.2.2.1 label-route-capability
|
[RT1-bgp]dis route-policy asbr Route-policy : asbr permit : 0 apply mpls-label | [RT2-bgp]dis route-policy RT2 Route-policy : RT2 permit : 0 apply mpls-label |
如上配置BGP已经建立成功,并且策略应用成功,但是查看路由应该被选为最优的却不是最优,检查路由表又没有相同网段路由存在:
[H3C-GigabitEthernet0/1]dis bgp vpn vpn vpn200 routing-table label
* 19.19.19.19/32 2.2.2.2 NULL/1025
* 103.103.103.103/32 2.2.2.2 NULL/1024
*>i 107.107.107.107/32 104.104.104.104 1029/1028
Label BGP分配标签时候还要求其相应的接口使能MPLS,这样才能正确的形成下一跳的隧道,并正确转发。在接口上使能和去使能mpls功能是测试MPLS L3vpn特性的一种很常见和重要的测试方法;而基于子接口的测试也是常发现问题的手段之一。
收到一条vpnv4路由,下一跳可达,而且在全局VRF路由表里中也是唯一,但是始终无法达到最优。
<H3C>display bgp vpnv4 all routing-table
Total number of routes from all PE: 1
Route Distinguisher: 5060:1
Network NextHop In/Out Label MED LocPrf
*>i 2.2.2.0/24 102.102.102.102 NULL/1027 0 100
Total routes of vpn-instance vpn200: 6
Network NextHop In/Out Label MED LocPrf
* i 2.2.2.0/24 102.102.102.102 NULL/1027 0 100
*> 107.107.107.107/32 9.1.1.2 1028/3 0
VRF中的路由在优选的时候,对于普通L3VPN,H3C COMWAREV5平台的实现是必须保证其下一跳的隧道的存在,通过使用命令display tunnel-info all命令可以查看目的网段102.102.102.102的隧道是否存在,如果不存在则不会最优,请检查标签分配LDP或者BGP的配置。
比如存在vpn-a和vpn-b,相应接受VT属性为1:1和2:1。在vpn-a视图下通过export route-policy命令强制改变本vpn路由的VT属性增加2:1,但是vpn-b实例不会接受到这些vpnv4路由。
H3C COMWAREV5平台目前实现是通过vpnv4获取的路由在刚开始接受时即会检查其VT属性然后决定下发到哪些vpn中,如果是在接受到VPNV4路由后再改变其VT属性不会影响以前所做的决定。当然,如果是VRF本身获取的路由,改变其属性会影响到路由下发其它VRF中。
缺省情况下,某个VPN路由不会发布到其他VPN中,可以通过在VPN实例视图下配置vpn-target命令将当前VPN实例的路由发布到其他VPN实例或将其他VPN实例的路由引入到当前VPN实例。
另外,还可以使用系统视图----IP VPN实例视图下的import route-policy、export route-policy命令,以比采用扩展团体属性更精确地方式控制发布VPN实例路由。
H3C COMWAREV5平台支持丰富的路由策略来控制路由的接受和发送,针对bgp对等体或者对等体组有如下方式:
1) as-path-acl,AS路径过滤控制列表;
2) ip-prefix,IP前缀列表(支持IPv6,即ipv6-prefix);
3) route-policy,路由策略;
4) filter-policy(advanced acl),路由应用过滤策略;
其中route-policy又支持多种控制规则,比如:
1) if-match as-path,匹配AS路径列表;
2) if-match community,匹配团体属性列表;
3) if-match extcommunity,匹配扩展团体属性列表;
4) if-match cost,匹配路由MED;
5) if-match interface,BGP不支持这种过滤方式;
6) if-match mpls-label,BGP支持,通过BGP分配标签可以代替IGP+LDP模式,在L3vpn的c2c以及跨域中得到大量应用;
7) if-match acl(advanced acl),匹配访问控制列表;
8) if-match ip/IPv6,匹配下一跳,可以指定acl或者地址前缀列表;
9) if-match ip-prefix,匹配地址前缀列表,同样也支持IPv6。
BGP号称路由中的王者,有很大一部分功劳归功于路由策略,可以说是其左右臂膀之一。针对路由策略的使用,各个厂商有其各自的规则。H3C COMWAREV5平台的路由策略配置和使用都相对比较简单,只要掌握以下几条基本原则,相关的问题就会迎刃而解。
1) 一个Route-policy的所有NODE之间是"或"的关系
2) 一个NODE内部所有"if-match"之间是"与"的关系
3) 一个"if-match"内部的所有参数之间是"或"的关系
简单来说,一个Route-policy可以由多个节点(node)构成,每个节点是进行匹配测试的一个单元,节点间依据顺序号(node-number)进行匹配。每个节点可以由一组if-match和apply子句组成。if-match子句定义匹配规则,匹配对象是路由信息的一些属性。同一节点中的不同if-match子句是“与”的关系,只有满足节点内所有if-match子句指定的匹配条件,才能通过该节点的匹配测试。apply子句指定动作,也就是在通过节点的匹配测试后所执行的动作——对路由信息的一些属性进行设置。
一个Route-policy的不同节点间是“或”的关系,系统依次检查Route-policy的各个节点,如果通过了Route-policy的某一节点,就意味着通过该Route-policy的匹配测试(不进入下一个节点的测试)。
而对于某些if-match子句,后面可以跟多个同类的并列参数,这些参数之间是“或”的关系,即满足其中一个参数的值,就满足了该if-match子句。
例如下面的配置:
route-policy 1 permit node 1
if-match cost 20
if-match route-type internal external-type1
route-policy 1 permit node 2
if-match cost 30
在route-policy 1中配置了两个节点node 1和node 2,而在不同的node中配置了不同的if-match子句。
很容易可以看出,满足node 1的条件是cost为20并且路由类型为OSPF内部或者外部type1路由。即对于if-match route-type internal external-type1来说,由于internal和external-type1是同一个if-match子句中多个并列参数,所以它们之间是“或”的关系,只要类型为internal或者external-type1的路由均算满足该if-match子句。
而对于node 1来说,它存在多个并列的if-match子句,它们之间是“与”的关系,所以必须同时满足
if-match cost 20
if-match route-type internal external-type1
这两个条件才算正在通过node 1的测试。
而对于node 2而言,只有没有通过node 1检测的情况下才会发挥作用,否则通过了node 1的检测就不再进入node 2的检测了。
注:如果node中的if-match条件匹配成功且if-match的条件是DENY,则不论node配置的是permit和deny继续匹配下一个node;如果所有的node都没有匹配成功,则按照DENY处理。对于不存在的路由策略默认通过!
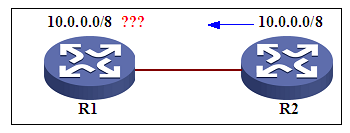
图3 BGP前缀过滤示例
如图3,R1上配置如下:
Peer X.X.X.X ip-prefix 1 import
ip ip-prefix 1 index 20 permit 10.0.0.0 16
很显然,配置的前缀列表是错误的,应该是permit 10.0.0.0 8,当进行前缀控制列表匹配的应该要注意掩码和规则的逻辑关系。
如图3,R2上配置如下:
Peer X.X.X.X route-policy 1 export
Route-policy : 1
permit : 0
apply community 1 2 3
apply extcommunity rt 0.0.0.0:0
R1收到路由后不会具备团体属性和扩展团体属性,为什么了?BGP默认是不发送团体属性和扩展团体属性(当然vpnv4默认发送扩展团体属性)的,所以要想将这类属性发送出去必须针对指定的对等体或者对等体组设置命令:
Peer X.X.X.X advertise-community,发送团体属性;
Peer X.X.X.X advertise-ext-community,发送扩展团体属性,两者没有耦合关系。
使用as-path控制列表来进行路由控制是比较复杂且难以记忆的控制方法,主要是正规则表达式的使用,这方面可以参考常用BGP正则表达式应用相关文档。
在一个AS内,IBGP必须要求在逻辑上是全连接的,但随着网络拓扑的日益复杂,IBGP的全网连接开销很大,为了解决这个问题,引入了反射机制。路由反射器概念的基本思路是:指定一个集中路由器作为内部对话的焦点。多个BGP路由器可以与一个中心点对等化,然后多个路由反射器再进行对等化。路由反射器的特点:简易理解、移植方便(不用更改现有网络拓扑结构)、兼容性好(不用所有的路由器都支持反射机制,反射器对于客户来说是透明的)
在RFC2796中规定:“In addition, when a RR reflects a route, it should not modify the following path attributes: NEXT_HOP, AS_PATH, LOCAL_PREF, and MED. Their modification could potential result in routing loops.”即反射器反射路由时,不应该修改NEXT-HOP,AS_PATH,MED以及LOCAL_PRE属性。同时在反射器上即使应用路由策略修改属性,新的属性也不应该应用到被反射的路由上。
H3C COMWAREV5平台反射器支持普通BGP、BGP4+、VPNV4、BGP VPN,在指定视图下进行如下配置:
reflector cluster-id 4294967295 //反射器ID
peer 104.104.104.104 reflect-client //指定IBGP peer作为反射器客户端
reflect between-clients //默认已配置,反配置则取消反射功能
反射的配置相当灵活,除了普通的配置方案外,为了加强反射技术的健壮性和灵活性,还可以配置冗余反射器和嵌套反射器:
由于AS域内逻辑结构的改变,反射器成为路由发布的瓶颈,一旦反射器出问题,那么整个域内的路由传递就会受到很大的影响,在这种情况下,可以通过配置冗余反射器来解决,即:一个群内存在一个以上的反射器,各反射器CLUSER_ID是一样的,都与客户进行全连接,当一台反射器出问题时,另一台反射器仍能正常工作,相当于备份功能。冗余反射的概念可以进一步参考下文。
除此以外,还可以配置嵌套反射器,即在一个群内嵌套配置一个反射群,反射群与该群的CLUTER_ID是不同的。嵌套反射器在VPNV4用的比较多,比如MPLS L3vpn环境中,通过多级反射来分担PE的压力。
为了避免路由环路,引用了originator-id属性和cluster-list属性,originator-id属性是由反射器产生的,它的值是始发这条路由的邻居的router-id;cluster-list也是由反射器产生的,反射器如果发现update报文中有了cluster-list属性,就把自己的cluster-id添加到后面;如果没有,就创建一个cluster-list属性,把自己的cluster-id放到上面,再向其他邻居发布;如果发现与本地雷同,则会丢弃该路由以避免环路。cluster-id的值可以在反射器上配置,如果没有配置,缺省使用反射器的router-id。
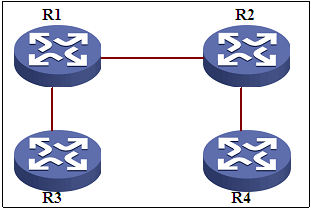
图4 BGP反射示例
如图4,R1和R2为RR,R3和R4为RRC,R4发布一条路由,R2收到了,但是R1和R3都没有收到。为什么?
发射路由在发送过程中会携带一个originator-id属性和一个cluster-list属性。其中originator-id的值是始发路由器的ID,cluster-list的值为沿途反射器的cluster-id。当客户机收到反射路由后会检查路由的这两个属性,如果在收到的路由中的originator-id属性中发现了自己的Router ID,就会拒绝该路由。这里原因为R1和R4的BGP进程具备相同的ID。
如图4,R1和R2为RR,R3和R4为RRC,R4发布一条路由,R2和R1都收到了,但是R3没有收到。为什么?
发射路由在发送过程中会携带一个originator-id属性和一个cluster-list属性。其中originator-id的值是始发路由器的ID,cluster-list的值为沿途反射器的cluster-id。当客户机收到反射路由后会检查路由的这两个属性,如果在收到的路由中的cluster-list属性中发现了自己的cluster-id,就会拒绝该路由。所以原因为R1和R2设置了相同的cluster-id,R1收到R2反射过来的路由后,会将路由丢弃而不会转发到R3。
如果R1和R2具备相同的cluster-id,而R3还要收到R4路由的话,可以用到前面提到的冗余反射概念,将R3也连到R2上,这样R1和R2都是RR而且具备相同的cluster-id,形成冗余反射环境,R4的路由会直接发射到R3上。
反射器的IBGP邻居有两类:客户和非客户邻居,反射器同客户一起形成一个群,群内的客户不应再与群外的BGP邻居形成IBGP连接。一个AS内所有的路由反射器和非客户机构成全闭合网。
1) 反射器从非客户收到的路由发向所有客户;
2) 由客户收到的路由会发向所有客户以及非客户(包括发送者本身);
3) 由EBGP邻居收到的路由发向所有客户以及非客户。
被反射的路由其属性不应该被改变,比如在测试中经常忽略的联盟属性等都不应该被反射器改变。
配置BGP路由反射,可以减少IBGP连接,反射到客户端的路由要在CLUSTER_LIST由属性中添加自身的cluster-id,但cluster-id的配置也不是必需的。当BGP配置reflector cluster-id后,即采用所配置值,当没有配置该值时,BGP将把local router id添加到对应CLUSTER_LIST路由属性中。
在RFC3065中定义:“This document describes an extension to BGP which may be used to create a confederation of autonomous systems that is represented as a single autonomous system to BGP peers external to the confederation, thereby removing the "full mesh" requirement. The intention of this extension is to aid in policy administration and reduce the management complexity of maintaining a large autonomous system.”可见联盟同反射类似,都是为了解决大规模网络中IBGP全网连接的问题。联盟的概念基于一个AS可以被分为多个子AS,子AS内使用IBGP全闭合网,子AS之间以及联盟本身与外部AS之间使用特殊的EBGP连接。虽然子AS之间的路由经EBGP交换,所有的IBGP规则仍然适用,因此对于AS外的路由器来看一个联盟就象一个单一的AS。EBGP下个中继、量度值和本地优先值仍然在内传送。
参与联盟的路由器一般遵循如下配置:
confederation id 6500 //大AS号,一个联盟内一致,不能与本地AS号相同confederation peer-as 600 //本地相连子AS的AS号
在RFC3065中新增加了两个为联盟定制的属性,即:
1. AS_CONFED_SEQUENCE: ordered set of Member AS Numbers in the local confederation that the UPDATE message has traversed;
2. AS_CONFED_SET: unordered set of Member AS Numbers in the local confederation that the UPDATE message has traversed
增加这两种属性是为了防止联盟内部的环路。
对于AS_CONFED_SEQUENCE和AS_CONFED_SET,联盟内处理方式大致与AS_SEQUENCE和AS_SET相同,同时:
1) 当路由在联盟内子自治系统间传递时,不应修改AS_PATH属性。
2) 当路由在联盟内子自治系统间传递时:
a) 若第一个AS_PATH是AS_CONFED_SEQUENCE,BGP将自己的子自治系统AS号加在最左端。
b) 否则,创建一个AS_CONFED_SEQUENCE,包含自己的子自治系统AS号。
3) 当向联盟外EBGP传递路由时:
a) 若第一个AS_PATH是AS_CONFED_SEQUENCE,将后续的AS_CONFED_SEQUENCE和AS_CONFED_SET删除,至b)。
b) 若第一个AS_PATH是AS_SEQUENCE,则将联盟AS加在最左端。
c) 若第一个AS_PATH是AS_SET,增加一个AS_SEQUENCE,将联盟AS加在最左端。
4) 对于本地初始路由的传播:
a) 向本自治系统内IBGP发送,空的AS_PATH属性。
b) 向联盟内,本自治系统外EBGP发送,带有AS_CONFED_SEQUENCE属性。
c) 向联盟外EBGP发送,带有AS_SEQ属性。
RFC1965中规定:AS-PATH Segment Type 3是AS_CONFED_SET属性,Type 4是AS_CONFED_SEQUENCE属性。而过去C友商把Type 3作为AS_CONFED_SEQUENCE属性,Type 4不使用。这样导致其发送的BGP update报文中,联盟的AS-PATH属性的格式和RFC不一致,导致互通过程我司不能识别合法的带有联盟的AS-PATH属性的BGP报文。过去为了达到互通的问题,需要配置confederation nonstandard命令以兼容友商的处理。
H3C COMWAREV5平台等价BGP路由的实现有着自身的实现,具体如下:
1) 参与BGP负载分担特性的路由必须为有效路由;
2) 参与负载分担的BGP路由ORIGIN,LOCAL-PREFERENCE,MED以及AS-PATH路径属性必须相同。BGP根据路由来源分为IBGP学到的路由,EBGP学到的路由,NETWORK命令引入路由,IMPORT-ROUTE命令引入路由,自动聚合路由以及手动聚合路由。不同起源之间的路由不形成负载分担;
3) 来源不同的BGP路由之间不形成负载分担;
4) 标签路由与非标签路由之间不形成负载分担,标签路由是指遵循RFC3107的BGP公网带标签路由;
5) 反射路由和非反射路由之间不形成负载分担;
6) 下一跳相同的BGP路由不形成负载分担;
7) 转发路由时,多条等价路由只随机选取一条路由并向外发送;
在保证如上规则后,还需要在BGP视图或者BGP VPN视图配置等价负载分担命令balance,默认不进行负载分担,H3C COMWAREV5平台目前支持最大等价路由数目为8条。
IBGP负载分担路由在配置反射的情况下向IBGP邻居转发等价路由时,不改变下一跳,下一跳为选中的等价路由初始下一跳;其他情况下,下一跳为形成负载分担的BGP本地地址。
BGP默认不形成等价路由。当存在等价路由后,在BGP或者BGP vpn视图下设置balance命令,可以使能等价路由功能。等价路由的形成具有很多限制,可以参考7.1节。
理论上对等体之间建立多个peer可以很容易形成等价路由,但是要注意这样带来的环路影响。同时通过引入IGP路由在自治域间形成等价路由也是比较常见的方式。比如在Multihomed AS拓扑中常会用到负载分担特性,当然这种简单的负载分担是不区分流量和业务,而是统一分配。
还有一种负载分担方法即根据不同业务和流量进行整体上的负载分担。如图5,针对不同业务X和Y的路由设置不同优先级,导致业务X的流量从link1通过,业务Y的流量从link2通过。
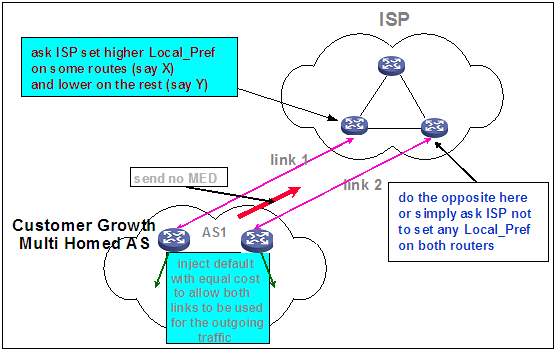
图5 BGP负载分担
对于来自域间的路由,在进入本地AS系统后常会通过设置边界路由器的本地优先级,导致路由在进行选择的时候存在主备,而边界路由器之间存在备份,在全连接中经常用到这种备份方法。如图6所示,customer的聚合路由通过两条路径发送到ISP后在两台边缘路由器上会形成两条路由,但是由于优先级的不同在传递到最上面的ISP路由器后会进行优选导致有主备之分,这样两者之间就建立了备份链路。
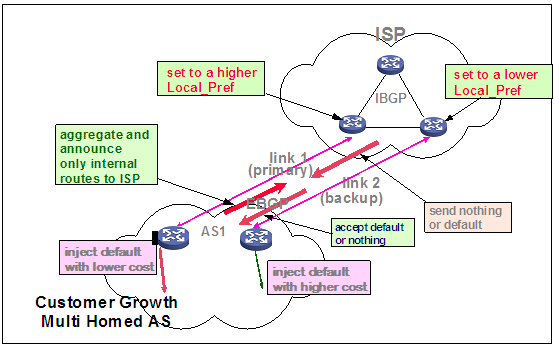
图6 BGP链路备份



 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友