文/程锋章
在过去的几年中,人们对边界网关协议(BGP)进行了大量的研究和思考。基于现状,在目前的互联网中甚至是在任何运行BGP协议的私有网络中对BGP进行大规模更换几乎是不可能的。因此考虑通过引入新的功能来增强BGP以满足新的需求。近年来,BGP在提高性能、增强可靠性、提高安全性、以及可扩展性方面取得了不少的进展。
性能优化的研究方向很多,比如路由决策、路由更新以及路由收敛等,各个厂商都有其内部的一些实现来更好的满足实际需要,不再一一展开详述。在H3C设备上针对BGP提供keep-all-routes特性,该特性用来保存所有来自对等体/对等体组的原始路由信息,即使这些路由没有通过已配置的入口策略。这样在策略控制更改后能够迅速进行新的路由决策和更新。当然目前的研究更多的是集中如何提高路由的收敛性能上。
BFD提供了一个通用的、标准化的、介质无关、协议无关的快速故障检测机制,BFD在两台路由器上建立会话,用来监测两台路由器间的双向转发路径,可以为各上层协议如路由协议、MPLS等统一的快速检测两台路由器间双向转发路径的故障。BFD本身并没有发现机制,依靠被服务的上层协议通知其该与谁建立会话,会话建立后如果在检测时间内没有收到对端的BFD控制报文则认为发生故障,通知被服务的上层协议,上层协议进行相应的处理。
BGP协议的keepalive时间间隔缺省为60秒,最小可以配置为1秒,这样holdtime缺省为180秒,最小为3秒,邻居关系的检测比较慢,对于报文收发速度快的接口会导致大量报文丢失。通过BFD进行快速故障检测,可以实现邻居关系的快速检测,加快协议收敛,类似OSPF的快速hello特性。
路由更新早在BGP提出的时候已经发展成熟,属于路由协议中必不可少的一部分,通过定时的更新路由报文来满足实际需要,并且针对IBGP和EBGP更新周期设置不同的默认值,H3C设备IBGP默认更新周期为15秒,EBGP则为30秒。
实际上这种实现也有其缺点,在一定程度上可能会降低路由收敛的速度、部分路由的震荡可能会影响到其它路由的收敛,实现过于保守。在RFC4271中规定指定对等体在发送或者撤销路由过程中必须间隔MRAI(MinRouteAdvertisementIntervalTimer),当对等体完成路由更新后启用MRAI定时器,在这个时间内对等体不再发送更新或者撤销消息。如果有新的更新或者撤销报文,需要等待定时器超时后发送。这个更新过程完成后再次启用MRAI定时器重复之前步骤。通过该方法能够避免持续路由震荡对设备造成影响,提高设备稳定性,在一定程度上能够提高收敛性能。
在实际应用中考虑到AS内部要求快速收敛,所以针对IBGP设置的MRAI要比EBGP小。由于该方法并不能控制路由决策,当MRAI超时后,最近一次被优选出来路由将被发送出去,该路由可能不是最优的路由。针对IBGP邻居或者PE-CE关系的EBGP邻居,在这种情况下可以调小MRAI。
在RFC 4724(Graceful Restart Mechanism for BGP)中讲述了一种帮助减少BGP重启对路由的负面影响机制,而在最新的 RFC 4781(Jan 2007 Graceful Restart Mechanism for BGP with MPLS)继续扩展该机制以便在BGP携带MPLS标签时,减少BGP重启对MPLS转发的负面影响。该机制对于BGP NLRI中携带的地址类型是不可见的,因此它可以在BGP中携带的任何地址族中工作。
为了保证LSR在其控制平面重启(尤其是BGP重启)时能够保持其MPLS的转发状态,需要保证此过程中不对经过该LSR的LSP造成干扰。在RFC 4781中的扩展机制和Graceful Restart Mechanism for BGP一起来实现该目标。
RFC4781中规定LSR使用Graceful Restart Capability向对等体进行能力通告,通告中的SAFI需要在NLRI字段中包含地址前缀和相应的标签。LSR控制平面重启后遵循RFC4724中的处理过程。在此过程中如果LSR能够保持MPLS转发状态,LSR将通过对所有AFI/SAFI的Graceful Restart Capability设置适当的Flag域。这里所说的MPLS转发状态是指入标签到出标签、下一跳或者地址前缀到出标签、下一跳的映射。在重启过程中不需要保留IP转发状态。重启的LSR完成了路由选择后,通告路由时标签的选择有以下三种情况:
第一种情况:
a) 路由器选择的最优路由是和标签一起接收的;
b) 该标签不为空;
c) LSR将自己作为路由的下一跳;
LSR在MPLS转发状态中搜索<出标签下一跳>和收到的路由中一致的表项。如果存在该表项,取消该表项的老化状态。找到的表项是(入标签,<出标签下一跳>)而不是(前缀,<出标签下一跳>)时,LSR在向邻居通告时使用入标签。找到的表项中没有入标签或者没有这样的表项时,LSR在向邻居通告路由时将选择一个没有使用的标签。
第二种情况:
a) 路由器选择的最优路由时没有标签、空标签、或者该路由是由路由器自己产生的;
b) LSR将自己通告为该路由的下一跳;
c) LSR必须为该路由分配一个非空标签;
LSR在MPLS转发状态中查找需要进行标签弹出操作并且下一跳相同的表项。如果存在该表项,LSR在向邻居通告路由时使用该表项中的入标签;如果不存在该表项,那么在向其他邻居通告路由时将选择一个没有使用的标签。
上面说的是LSR对于相同下一跳分配相同的标签。对于LSR将为每条有相同下一跳的路由分配一个不同的标签的情况,LSR在重启过程中不仅需要保留<入标签,(出标签,下一跳)>的映射,还要保留和该映射相关联的地址前缀。此时LSR将在MPLS转发状态中查找包含以下内容的表项:
(a)标签已弹出(意味着没有出标签);
(b)路由下一跳相同;
(c)具有相同前缀的表项;
如果表项存在,LSR在向邻居通告时使用表项中的入标签;如果没有该表项,那么在通告路由时将选择一个没有使用的标签。
第三种情况:
这种情况适用于重启的LSR没有将自己设置为BGP下一跳的情况。此时LSR在通告特定NLRI的最佳路由时使用和路由一起接收的标签。如果没有标签和路由一起接收那么LSR在通告时也不带标签。
BGP有一个很重要的特性即是防止环路,但是在某些情况下环路的确存在而且无法避免,导致路由不断更新和变化始终无法收敛。避免最佳路径迁移的方法可以通过将选定的最佳路由设定为最佳路径不再改变防止环路的出现。具体方法见下图:
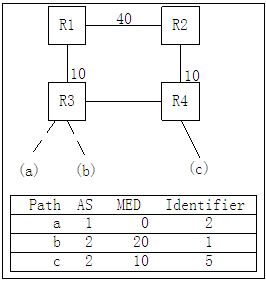
当路由C不存在时,在R3上面应该是选择B(因为默认EBGP路由不比MED值,所以选择BGP ID小的即B);当C存在的时候在R3上面应该是选A(因为C比B优,但是A又比C优)。所以C撤销时会触发A切换到B,引起最佳路径切换。
当R3通过比较两个EBGP路由选定A为最佳路由后,则该路由被设定为最佳路径而且不再改变,这样即使C撤销或者反复震荡也不会影响R3设备AS域间路由的变化,提高了网络设备稳定性。
H3C设备提供了AS稳定迁移功能。在实际应用中,运行BGP的路由器一般情况下是只能属于一个AS,但是可能由于某种原因该AS可能需要迁移或者和其他AS进行合并,H3C的BGP命令FAKE-AS就是用来解决AS迁移过程所遇到的麻烦。该特性具体介绍可以参看章节《BGP新特性》。
传统BGP在变更相关能力配置的时候,需要断掉邻居关系重新建立。举个例子:一台正在转发数据的BGP路由器,由于需要提供VPLS能力,所以需要配置上相关的能力地址族。这样必然导致BGP邻居重新建立,从而引发数据丢失、整网路由震荡、路由重新学习等问题。动态更新邻居能力这个特性,可以在配置新的能力地址族的时候发送新的OPEN报文,同时邻居动态地把新增加的能力记录下来。这样可以保证在邻居关系不会重新建立前提下,提供了更多其它业务服务,提高了转发稳定性。为此定义了一种新型BGP报文,type为6,其内容如下:

先看一个小故事,某年2月24日,Google You Tube视频服务意外中断了两个小时。原因起始于巴基斯坦,该国的ISP(互联网服务供应商)决定切断对You Tube的访问,在网络上发布“错误”的BGP路由,即开始发布自己是You Tube 所属208.65.15.3.0网络空间256个地址的正确BGP路径。
由于这样的BGP路由远比正宗You Tube网站发布的还要详细,根据即时网络流量监控公司Renesys的时间表,亚太地区的网络服务商在15秒内就开始将You Tube的访问导向这家巴基斯坦的ISP,而其他地区的路由器也在45秒后就开始跟进。很快,这些数据同时也通过网络传送给了中国香港的ISP服务商PCCW。后者又通过Internet把这些数据传播给了其他ISP。一场大范围的You Tube访问中断就此出现。
那么,为何全球的路由器都会“误入歧途”?直接原因是PCCW没有检验来自他们客户的BGP数据,而最值得人们关注的则是,像Google在防止这种问题上仍然无能为力。Arbor Networks公司首席研究官Danny McPherson说:“他们不能阻止Internet上的某人发布他们的地址空间,这是个巨大的安全漏洞。”这是一起典型的非法路由注入事件。
目前为止,各类互联网服务商只能事先“相信”其他服务商不会刻意捣乱或者去拦截他人的互联网地址。而一旦有类似的情况发生,则可以采用人工介入加以修正,比如这次事件中,You Tube就通过随后加入更精确的广播,从而给路由器一个正确的导向。但是考虑到这种错误广播的出现次数可能还会增多,研究人员已经开始建议设立一种拦截警示程序,当互联网地址的虚拟地址变更时,网络供应商可自动获得通知。此外,这类事件也有望让人们更加重视Secure BGP这类技术,它采用加密方式来确认哪些网络供应商拥有网络地址并有权广播。问题是,这一技术虽然早在1998年提出,但被认为复杂度太高,要真正采用可能还需要做很多工作。
事实针对BGP弱点的攻击形式很多,在《draft-convery-bgpattack-00.txt》中有一些介绍,比如针对MD5 (RFC 2385) Attacks、建立未经授权的BGP连接、发布和注入未经授权的BGP路由、发送欺骗性质或者非法的BGP消息、影响BGP连接建立的TCP报文攻击等。还有不少潜在的风险,比如路由震荡、聚合路由、BGP团体属性等都有可能成为被攻击的地方。下面简单介绍一些新的安全方面的进展:
TTL安全检测机制主要是用来防止多跳攻击。BGP存在两种邻居关系:内部邻居关系(IBGP)和外部邻居关系(EBGP)。建立这两种邻居关系时,IBGP不对TTL进行检测,EBGP缺省发送TTL等于1的协议报文。如果RA与RB开启了TTL安全检测功能,设定从RB转发给RA的BGP协议报文的TTL必须为255,同时RA拒绝接受任何TTL比254小的BGP报文。那么即使存在攻击者其报文TTL最大为255,转发给RA的时候TTL必然减2,这样即使RA接受到一个TTL=253的协议报文也会自动丢弃,从而达到防攻击的效果。
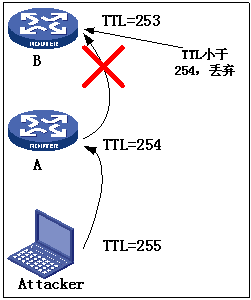
图3 TTL安全检测
当网络存在安全威胁的时候,通过TTL安全检测可以防止潜在的安全隐患。RFC3682(The Generalized TTL Security Mechanism (GTSM))详细描述了这种机制。
《draft-turk-ertb-00.txt》文档描述一种使用BGP团体属性进行远程触发特定目的网络的黑洞路由技术,黑洞路由可以在选择的一些BGP路由器中应用,而不需要在网络中所有的BGP路由器中应用;同时还提出了利用BGP团体属性的“攻击流量分析隧道”(“sinkhole tunnel”,本义是污水池隧道技术),该技术可以将网络中的流量牵引到一个指定路由器中进行分析。
当前的远程黑洞技术依赖于将曾经经历过某种异常(包含攻击)的一些目的网络地址在BGP中通告,该通告是由BGP域中的一台路由器来完成,在通告中将这些网络地址的下一跳修改并将它指向在RFC1918中指定的私有地址范围内的一个地址(10.0.0.0~10.255.255.255,172.16.0.0~172.31.255.255,192.168.0.0~192.168.255.255)而在Internet中的大多数路由器尤其是边界路由器都会配置将上述地址的下一跳指向接口为null0的静态路由。BGP speaker在BGP speaker在收到上述通告后在自己的路由表中将安装该目的网段的路由并将下一跳指向私有地址范围内的一个地址,路由器在执行路由查找时将决定以这些私有地址为目的地址的数据包转发到什么接口,由于在路由器中有一条静态路由将这些地址为目的的路由指向null接口,因此这些流量将被丢弃因此攻击者对所通告的网络不可达从而不能攻击。
这项技术对网络基础设施减轻了攻击流量的负担,另一方面,上述网段在BGP运行的区域是不能运行的即使某个BGP speaker没有将RFC1918地址指向null接口,修改下一跳将导致其合法的目的地不可达,当然大部分ISP不会将这些黑洞在所有时间内存在,他们仅在一段时间内将黑洞打开将进入网络的所有路由都丢弃,依靠大部分路由器都有对丢弃的流量报文给源地址发送ICMP不可达报文的配置,可以将这些ICMP报文发到某一个特定地址上来搜集这些ICMP不可达报文。从这些报文中将可以找出上述被丢弃流量是从那些边界路由器进入网络的,然后运营者将选择停止从那些路由器进来的流量。
ISP有几种方法来减少攻击对网络的冲击,以上述将受攻击目标网络引入黑洞并将相应的ICMP不可达报文引出来从而确定攻击流量的入口等措施开始,然后隔离相应接口和对等体网络,最后安装ACL,限速策略或将这些流量转发到null接口。其他的技术可以用一种可以用一种技术识别DOS攻击并识别攻击流量从那些端口进入然后利用Netflow,这样比较省时省力。这些技术都依赖在特定路由器上手工制止攻击流量。
本文档提出一种远程触发可选择的一些路由器将以受攻击网络为目的地址的流量转发到null接口或者将这些流量转发到“攻击流量分析隧道”。该技术不使用关于攻击流量的ACL或限速策略,也不将攻击流量的下一跳地址修改为RFC1918地址。它仅仅通过边界路由器的BGP的团体属性改变路由选择。
首先ISP需要为每个可能成为网络攻击流量入口的边缘路由器分配一个唯一的团体值。以一个包含两个边界路由器R1和R2的小ISP网络为例,假定AS为65001,ISP可以为R1分配团体值为65001:1,为R2分配团体值为65001:2,为R1和R2全体分配团体值65001:666,然后在边界路由器上进行如下操作:
1. 在R1 R2上配置将RFC1918地址指向null接口的静态路由;
2. 配置匹配BGP本地产生的网络前缀的AS-Path访问列表;
3. 配置匹配ISP为本路由器分配的BGP团体访问列表(比如65001:1 for R1);
4. 配置匹配ISP为所有路由器分配的BGP团体访问列表(比如65001:666 for R1and R2);
5. 在BGP进程下IBGP输入路由策略将应用于如下逻辑操作如下步骤按照逻辑与的顺序:
a..允许通过如下匹配的路由;
I. 与特定路由器的团体值匹配(比如65001:1, for R1);
II. 与本地产生的BGP通告路由的AS-PATH匹配;
III. 将BGP路由的下一跳设置成RFC 1918地址;
IV. 将BGP的团体属性修改成no-advertise;
b. 允许通过如下匹配的路由
I. 与所有路由器的团体值匹配(比如65001:666, for R1和R2);
II. 与本地产生的BGP通告路由的AS-PATH匹配;
III. 将BGP路由的下一跳设置成RFC 1918地址;
IV. 将BGP的团体属性修改成no-advertise;
这些策略在R1和R2上配置后,ISP在受到攻击的情况下,在BGP中通告受攻击网络同时带上引入攻击的路由器的团体值,并保留其实际下一跳,IBGP将该路由通告到AS内所有路由器,除了与这个团体值匹配的路由器外,其他路由器将忽略该团体值并在路由表中安装带有合法下一跳地址的该路由,而与该团体值匹配的路由器将安装该路由并将其下一跳修改为RFC1918地址,然后将他转到null接口,匹配本地通告的路由是保证EBGP用户不会错误地使用该团体值,从而将该网段的数据包引入null接口。
该技术在标识为攻击流量转发的路由器上停止转发到合法目的网段的流量,因此网络中的其他到达合法目的网络地址的流量将不受影响。
“攻击流量分析隧道”进一步发展该增强的远端触发黑洞路由技术,有必要观察这些攻击路由以便将来分析。该需求增加了复杂性,通常在广播接口在遍历端口(spanned port)通过安装网络监听软件将流量输出分析;另一种方法是发送一个包含攻击主机地址的网络地址到BGP域,将下一跳地址改变为攻击流量分析设备。进行记录并且分析。
当需要记录攻击网络地址并进行数据包级别的分析时,攻击流量隧道的概念应运而生。这个概念的思想是当流量从隧道的一端进入后将会从另一端出来,这个概念在流量转发时下一跳地址没有改变时有实际意义。
首先攻击流量分析路由器sinkhole router和网络监听分析sniffers工具连接在一起,这些将所有的可能从其他AS引入数据包的边界路由器到sinkhole router之间的隧道可以通过比如MPLS TE来建立。这样允许利用团体值的技术来将目标网段的下一跳改变成一系列的/30子网(该子网的两个地址连接隧道的两端),换言之,边界路由器将下一跳变成隧道另一端的sinkhole router,AS内的其他路由器对于通告中预先设定的团体值忽略;由于改变路由匹配在其他地方不存在,如果合法的流量从网络的其他部分进入AS,其下一跳不会被改变攻击流量在sinkhole被终结。如果需求不要求中断流量而是在分析后重新送回到流量的目的地,那么流量将被重新送回原来网络,路由协议要保证将数据包重新送到原来的地址中。
目前相关技术有RFC文档3882(Configuring BGP to Block Denial-of-Service Attacks),通过配置BGP来防止DOS攻击,作者是同一人,感兴趣可以看看。
IPSec(IP Security)是IETF制定的三层隧道加密协议,它为Internet上传输的数据提供了高质量的、可互操作的、基于密码学的安全保证。特定的通信方之间在IP层通过加密与数据源认证等方式,提供了以下的安全服务:数据机密性(Confidentiality)、数据完整性(Data Integrity)、数据来源认证(Data Authentication)、防重放(Anti-Replay)。可以通过IKE(Internet Key Exchange,因特网密钥交换协议)为IPSec提供自动协商交换密钥、建立和维护安全联盟的服务,以简化IPSec的使用和管理。IKE协商并不是必须的,IPSec所使用的策略和算法等也可以手工协商。
实际上IPSEC的应用已经非常成熟,目前解决BGP安全问题的一个方法就是利用IPSEC加密BGP报文,保证数据的机密性等。实际上这种技术不算什么新的技术,虽然能从一定程度上防范未经过认证BGP报文的攻击,但是BGP攻击的方式很多,比如破坏TCP连接的TCP RST报文、带有欺骗性质的路由更新报文等,BGP over IPSEC对于欺骗性质报文的防范存在很多的困难。
根据draft-ietf-idr-route-filter-06.txt(Cooperative Route Filtering Capability for BGP-4)中描述到:在目前的BGP实现中一般由BGP speaker接收路由然后根据本地的路由策略将一些不需要的路由过滤掉。考虑到发送方路由的产生发送和更新以及接收方处理路由更新均需要消耗资源。文档定义了一种基于BGP的机制允许BGP speaker给对等体发送一系列输出路由过滤Outbound Route Filters (ORF)。对等体将应用这些过滤条件和对等体自己配置的过滤条件共同过滤要发送的路由,同时加强了安全控制。
ORF定义
ORF项目由<AFI/SAFI, ORF-Type, Action, Match, ORF-value> 一个ORF可以由一个或多个具有相同的<AFI/SAFI, ORF-Type>的ORF项目组成;Action控制对等体处理ORF Request的动作可以是ADD, REMOVE,REMOVE-ALL;Match为PERMIT或者DENY;
团体ORF-Type
团体ORF-Type允许用BGP团体属性来表示ORF,也就是说团体ORF-Type提供基于团体属性的路由过滤。团体ORF-Type由<Scope, Communities>组成。Scope表示对等体对于给定ORF request必须考虑的路由范围可以是EXACT或者NORMAL。EXACT表示让对等体仅仅考虑考虑路由的团体属性和ORF列表中给出的团体属性相同的部分;NORMAL表示让对等体可以考虑ORF列表中的团体属性列表的子集部分;
扩展团体ORF-Type
扩展团体ORF-Type允许用BGP扩展团体属性来表示ORF 也就是说扩展团体ORF-Type提供基于扩展团体属性的路由过滤扩展团体ORF-Type由<Scope, Communities>组成,Scope表示对等体对于给定ORF request必须考虑的路由范围可以是EXACT或者NORMAL;EXACT表示让对等体仅仅考虑考虑路由的扩展团体属性和ORF列表中给出的扩展团体属性相同的部分;NORMAL表示让对等体可以考虑ORF列表中的扩展团体属性列表的子集部分;
在BGP中携带ORF项
ORF项目是在BGP ROUTE-REFRESH消息中携带BGP speaker能够通过消息头带的长度中确定BGP ROUTE-REFRESH消息中是否携带了ORF项目。一个BGPROUTE-REFRESH消息可以携带多个ORF项目,只要这些项目的AFI/SAFI是相同的。从编码角度讲ORF包括公共部分和类型相关部分:公共部分由<AFI/SAFI, ORF-Type, Action, Match>组成
团体ORF-Type 类型相关部分
团体ORF-Type的ORF-Type值为2 由<Scope, Communities>组成,scope包括EXACT和NORMAL;
扩展团体ORF-Type 类型相关部分扩展团体ORF-Type的ORF-Type值为2,由<Scope, Extended Communities>组成scope包括EXACT和NORMAL。
ORF操作
能够从对等体接收ORF或者向对等体发送ORF的BGP speaker需要用BGP能力通告(RFC 2842)进行能力协商,需要实现ORF的BGP speaker需要支持BGP ROUTE-REFRESH消息(在RFC2918中定义)。BGP speaker在向对方通告ORF能力时不一定需要向对方通告BGP Route Refresh的能力。
BGP speaker向对等体通告ORF能力表示可以接受<AFI, SAFI, ORF-Type>,并且从对等体接收ORF能力表示对方希望给自己发送<AFI, SAFI, ORF-Type>。如果对于一个给定的<AFI, SAFI> 两者的交叉部分不为空,BGP speaker在从对等体接收到关于该<AFI, SAFI>的任何ROUTE-REFRESH消息前,不需要向对等体通告关于该<AFI, SAFI>的路由。这些ROUTE-REFRESH可以不包含任何ORF项,或者带有一项或多项ORF When-to-refresh域设置成IMMEDIATE。如果两者的交叉部分为空时则遵循普通BGP过程。
在BGP draft< draft-ietf-rpsec-bgpsecrec-09.txt>文档中提出一系列的安全性要求,对目前的应用有着较好的指导作用,比如AS路径和NLRI信息认证等。使用该机制来验证接收的路由信息中承载的自治系统路径的有效性。目前在该领域的研究较多,而且该文中提到的其它方法也在研究之中。
针对特定前缀的路径信息的保护大致可以包括一下四方面的内容:
A) 授权AS发布路由:路由前缀的所有者授权指定AS产生和发布其指定路由;
B) 检查AS:要求从某对等体收到的Update报文中路由信息的AS-path属性中的第一个元素匹配该对等体设置的AS号;
C) 检查AS路径可行性:AS-PATH列表符合as中规定策略中的有效列表;
D) 路由更新信息传输检测:比C更严格的检查项,主要是检查通过该AS的路由更新消息能够满足某一特定的安全要求,避免路由非法注入等攻击。
BGP这个协议本身已经不会有大的变动,由于其报文格式采用TLV编码,非常方便组合和修改。针对BGP的扩展应用很多,自从RFC2858(Multiprotocol Extensions for BGP-4,BGP-4多协议扩展,obsoletes RFC2283)发布以来就可以使BGP不仅仅具备IPv4能力,还能支持其它能力比如BGP4+、MPLS、Multicast等。同时一些新的能力协商也跟随着BGP的扩展应用不断加入进来。
自治域系统号(Autonomous System number,下文简称AS)是拥有同一选路策略,在同一技术管理部门下运行的一组路由器的集合。BGP的RFC里留给AS的范围是2个字节,所以AS的范围为1-65535,其中64512以上的为私有AS。但是鉴于IPv4地址空间不够这个前车之鉴,在RFC4893里记录了一个BGP的新功能——4字节AS(BGP Support for Four-octet AS Number一般用M.N来描述)。
由于BGP在邻居协商以及路由发送接受的时候都需要利用AS这个属性,所以RFC4893里也对相应的属性的扩展变化做出了解释。为了便于读者理解,下面列出了RFC4893定义的相关新的属性以及说明。由于该特性最大的变化是AS的变化,所以所有的属性扩展都是基于AS的相关属性,只是属性的TYPE值的变化,具体介绍可以参看章节《BGP新特性》。
早在<draft-ietf-L3vpn-bgp-ipv6>已经提出IPv6 VPN的概念,目前该draft已经形成正式的RFC4659。在理论上IPv6 VPN和IPv4 VPN没有什么区别。与IPv4相似的是,MP-BGP是MPLS VPNv6的核心部件。它被用于在SP骨干网上分发IPv6路由,具有相同的重叠地址、再分发策略和扩展问题的处理方式。先介绍一些简单术语:
1) 6VPE路由器——在基于IPv4的MPLS核心网络上提供BGP-MPLS IPv6 VPN服务的PE路由器。其基础是一个VPNv6 PE和双栈(IPv4+IPv6),双栈实现了面向核心接口的6PE概念。
2) VPNv6地址——一个VPNv6地址是一个24字节的标识符,以8个字节的路由区别符号(RD)开始并以16字节的IPv6地址结束。有时它被称为VPN IPv6地址。
3) VPNv6地址族——地址族标识符(AFI)定义了一个特殊网络层协议和子AFI(SAFI)提供的附加信息。AFI IPv6即SAFI VPN(AFI=2,SAFI=128)被认为是VPNv6地址族;
在IPv6 VPN中,尽管不希望在IPv6出现地址重叠问题,但地址仍旧使用RD来规划。同时定义一个新的网络层可达信息(NLRI)的三元组格式<长度,IPv6前缀,标签>,其目的是使用MP-BGP分发路由。一个VPNv6地址是一个16字节的IPv6地址,预先带有8个字节的RD,构成了24个字节的地址、如同IPv4一样,VPNv6前缀只在MP-BGP内有意义。
VRF概念对于熟悉MPLS的人来说是一个常用的概念,一个VRF定义为一个虚拟路由选择的转发表项,它绑定了一个私有的路由选择和转发表,即常提到的私网路由表。有人可能认为,既然IPv6带有自己的路由选择和转发表,那么应该有不同的IPv4和IPv6 VRF。实际上,尽管IPv4和IPv6路由选择表的确不同,但是从部署角度来看,共享一个VRF是非常方便的。目前可以看到的实现即是如此,在全局的VRF视图下增加IPv6地址族视图,这样一个VRF下面可以同时配置IPv4和IPv6的RD和route-target信息。总体来说,VPNv6的实现和IPv4较为类似,许多BGP特性比如反射、路由刷新、路由过滤、聚合等支持并无二样。
当前IGP协议对于MPLS TE的支持比较完备,比如isis和ospf都已经有相关的成熟实现和RFC支撑。MPLS TE是使用MPLS技术来实现TE,首先收集TE关心的链路信息,然后使用IGP算法满足某条流的特定约束条件计算出一条路径,再通过其信令协议RSVP-TE或者CR-LDP建立lsp隧道。
针对EGP协议的应用暂时没有,实际相关研究也不多。目前BGP也没有正式的RFC提出BGP支持MPLS TE,不过笔者在IETF上面发现一篇draft(draft-ietf-softwire-bgp-te-attribute-00.txt),是基于GMPLS信令协议的。拿过来简单分析一下,有兴趣可以关注一下。该draft定义一种新的BGP属性(Traffic Engineering),该属性是可选非过渡属性。

图4 TE属性字段编码格式
Switching Capability(Switching Cap)和Encoding字段的定义等同于 (RFC3471,Generalized Multi-Protocol Label Switching (GMPLS) Signaling Functional Description) 中Section 3.1.1所描述的定义。Reserved字段为保留字段在传输过程中必须设置为,在接收端被忽略。
Switching Capability specific information字段的内容跟Switching Capability字段有关,当Switching Capability是PSC-1, PSC-2, PSC-3, or PSC-4时候,它由最小lsp带宽和接口mtu组成,见图5:

图5 Switching Capability属性字段编码格式
当Switching Capability是L2SC时候,则不带该字段。当Switching Capability是TDM时候,它由最小lsp带宽和接口标识(Indication)组成,Indication字段表示该接口是支持标准还是私有的SONET/SDH(1表示标准,0表示私有)。
总体来说,在BGP扩展性上面TE的研究不是很多而且暂时看不到巨大的需求。在BGP扩展的研究中,还有许多比较有新意的内容,比如draft-boucadair-qos-bgp-spec-01.txt、draft-jacquenet-qos-nlri-04.txt中对于QOS的研究等,不过目前进展不大,这里不深入讨论。
针对BGP的缺点和应用,目前提出的改进方法和研究很多,以上只是从四方面描述一下目前的发展。其中收敛速度、策略和安全是BGP亟待解决的问题,为BGP发展提供了发展方向参考。然而不断对BGP进行逐步改进也促使我们进行思考:是对BGP进行小的改变使它越来越复杂?还是承受所有部署问题而更换BGP协议?



 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友