文/朱皓
Graceful Restart简称GR,字面意义是平滑重起,主要实现的能力是在路由协议重起的时候保证数据转发的正常,以保证关键业务不中断。
GR技术是属于高可靠性(HA, High Availability)技术的一种。HA是一整套综合技术,主要包括冗余容错、链路保证、节点故障修复及流量工程。GR是一种冗余容错技术,目前已经被广泛的使用在主备切换和系统升级方面,以保证关键业务的不间断转发。
随着网络设备普遍采用了控制和转发分离的技术,GR技术就成为了可能。在传统的路由器中控制和转发是由同一个处理器(RP:Route Processor)完成的,这个处理器既通过路由协议发现并维护路由,同时也维护着路由表和转发表。为了提高设备的转发性能和可靠性,中高端设备普遍采用了多RP的结构。负责路由协议等控制模块的处理器一般位于主控板,而负责数据转发的处理器则位于线卡上。这样在主处理器重起的时候才有可能不影响线卡上的数据转发。
基于上面的原因,目前实现GR的设备都需要有以下特征:双主控结构,并且线卡具有自己独立的处理器和内存等。
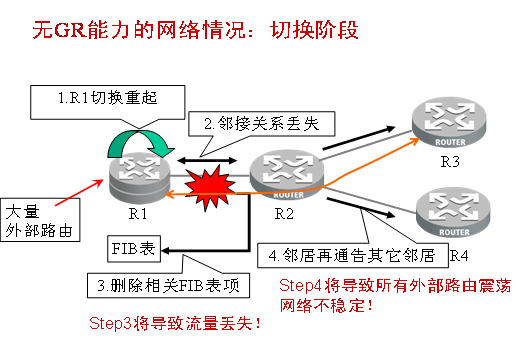
在没有使用GR的时候,因为各种原因出现的主备切换,都会造成短时间的转发中断,并且在全网造成路由振荡。通过图1可以看到问题所在。
如果R1是自治系统的ASBR,那么会通过BGP引入大量外部路由,当R1发生主备切换时,会造成下面的影响:
所有外部路由丢失,当R1恢复时,再次学到路由,造成网络路由振荡。
在R1的备份主控单元完成路由计算和发布之前,所有通过R1的数据转发中断。
R1的所有邻居需要重新进行路由计算,并改写转发表。
当R1恢复正常时,R1的所有邻居需要重新进行邻居协商和交互,并计算路由,改写转发表。
对于一个大型网络,尤其是运营商网络,对于这些路由振荡和业务中断是不可容忍的。
而使用GR技术则可以解决全部的问题。在R1与其它邻居建立邻接关系的时候,就会进行能力的协商。这样在R1进行切换的时候,它的邻居会维护邻接关系不变,并保持路由的稳定和正常的转发。除了R1的邻居,网络中的其它设备并不知道R1进行了协议的重起。
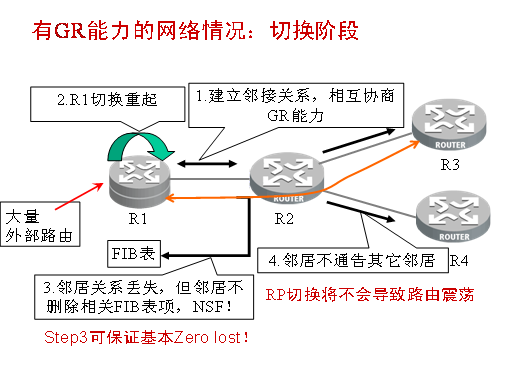
当然,如果R1在GR的过程中,网络拓扑发生了变化,那么可能会导致短暂的路由环路或路由黑洞。对于这个问题的处理方法,目前不同厂商的实现略有不同。与业务中断的危害相比较,是否可以忍受可能出现的,短暂的路由环路和路由黑洞,对这个问题的不同观点决定了在具体实现上的不同。
Ø GR特性仅适用于带双主控、线卡具有独立处理器的硬件平台。
Ø GR用于软件或硬件错误导致Active RP重起或Active RP失效;或者管理员的主备切换命令。
本文主要讨论OSPF中的GR技术。众所周知,OSPF是链路状态协议,邻居间需要维护链路状态信息库LSDB的同步,并根据LSDB计算路由。因此为了完成GR,对OSPF有下面的要求:
Ø 在GR的过程中,邻接状态不能改变,必须维护在FULL的状态。
Ø GR的周期是可选的,默认情况下使用RouterDeadInterval。
Ø 在GR过程中,必须保持转发表FIB不变,可以做相关标记。
Ø 当某些原因导致GR中断时,需要进行标准的协议重起过程,重新进行邻接的建立。
Ø 需要对OSPF做相应的扩展以支持GR特性。
从前面的介绍中可以看出,对于OSPF而言,一个完整的GR过程,需要至少2个设备完成,而这两个设备可以具有相同或者不同的能力。因此,根据能力划分:
GR Capable路由器
有GR功能的路由器:通常配备双RP,能在RP切换的时候,通告周边邻居,保持自己的转发表,切换后重建路由表。
GR Aware路由器
GR感知路由器:能懂得GR路由器的信令,配合在GR路由器重起期间保持邻接关系和通过GR路由器的转发表项。GR Aware设备只是需要识别GR信令,因此可能不具备有双RP,不能进行GR。但它可以配合有GR能力的设备来完成GR过程。毫无疑问,有GR能力的设备当然是GR感知的设备。
GR Unaware路由器
不能感知GR的路由器:不懂GR信令,不能协助GR路由器在RP切换时不间断转发,更不能执行GR。一般来说是系统软件没有GR特性或者GR特性被关闭。
从GR中完成的任务来看,分为GR Restarter(就是协议重起的设备)和GR Helper(就是协助完成协议重起的设备)两个角色。
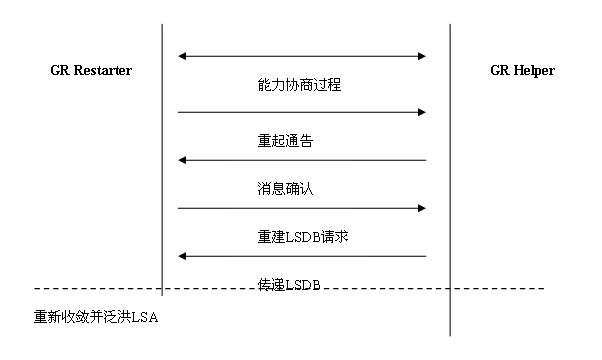
图3 GR的流程
目前有两种主流的实现标准:
Ø RFC 3623:Graceful OSPF Restart
Juniper,Redback,Nexthop,Procket等厂商采用的实现方法。
Ø Cisco IOS,IETF草案包括
draft- nguyen-ospf-lls-05.txt
draft-nguyen-ospf-oob-resync-05.txt
draft- nguyen-ospf-restart-05.txt
下面我们对这两种实现分别进行介绍。
RFC3623中定义的GR有两个重要的原则:网络拓扑要保持稳定;重起协议的路由器可以在重起过程中保持转发表。否则需要终止GR过程,进行标准的OSPF协议重起。
在GR的过程中,定义了GR Restarter和GR Helper的行为。GR过程是通过GR Restarter发出一个Grace-LSA的通告开始的。
RFC3623定义了发起GR的信号,Grace-LSA,该LSA是一个Opaque LSA,所以需要对OSPF进行扩展,以支持Opaque LSA。Opaque LSA是通过RFC2370进行定义的,这里我们稍做一下回顾。
RFC 2370:The OSPF Opaque LSA Option 定义了新的Opaque LSA类型,以提供扩展OSPF能力的通用机制,共定义了3种类型,包括:Link State Type 9,10,11。
Type 9:link-local scope,只在本地链路(子网)传播;
Type 10:area-local scope,在本区域内传播;
Type 11:AS scope,在OSPF进程运行的路由域内传播。
原Link State ID分为Opaque Type(1个字节)和Opaque ID(3个字节)两部分。
承载信息部分:由TLVs结构组成,没有特别定义LSA内容以提供通用机制。
根据各种类型OLSA的使用范围可以看出,GR技术中的Grace-LSA应该是使用类型9,是一个本地链路的LSA。对于Grace-LSA,Opaque Type字段为3,Opaque ID字段为0。在Grace-LSA的TLVs中,主要包括GR周期、发生GR的原因和GR Restarter的接口IP地址。
Ø 设备不会产生LSA;当收到源于自己的LSA时,不做处理,并认为有效。
Ø 在标准的OSPF过程中,当设备收到一个源于自己的LSA,会认为是上次重起前遗留的LSA。这个时候设备会生成一个序列号更大的LSA并泛洪或者提前老化该LSA。但是在GR过程中,设备通过从邻居获取LSA来得到重起前的网络拓扑,因此这时候只是接受,并认为有效。
Ø 不能下发路由项到转发表。
Ø GR设备通过侦听接口上的HELLO知道自己是否为DR,如果是DR,还会保持。
Ø 设备收到从邻居发来的hello报文,如果其中DR为自己,那么会保持在自己的hello中宣告自己为DR。
Ø 保证转发表的准确,并在重起过程中被保护。
Ø 解决保存各接口所使用的LSA序列号的问题。比如用时钟来产生序列号。这样可以保证在重起后序列号得到延续。
Ø 产生Grace-LSA,age=0,并给出GR周期。必须采用某种机制来确认邻居已经收到了Grace-LSA(采用OSPF同步LSDB的机制)。并将Grace-LSA中相关的参数保护起来,比如GR周期。需要注意的是,邻居确认收到Grace-LSA并不代表它一定具有帮助者的能力或者会帮助完成GR过程。即使一个不支持GR特性的设备,也会发出收到LSA的确认信号,但它不能帮助完成GR过程。
Ø 已经重建了所有邻居(可以通过从邻居那里获得的1、2类LSA中知道所有的邻接关系)
Ø GR设备收到一个不合逻辑的LSA。比如收到的LSA中不包括自己,或者自己的LSA中不包括这个邻居。这说明网络拓扑发生了变化。
Ø GR周期超时。
无论GR过程是否完成,都会进行标准的OSPF重新泛洪和路由计算,按照当前的链路状态产生LSA并泛洪,根据LSDB计算路由并下发到转发表。必须要完成的下面这些工作:
Ø 重新在所有关联区域泛洪1类LSA。
Ø 如果是DR,重新泛洪2类LSA。
Ø 重新计算路由并下发到转发表,产生必要的3、5、7类LSA。
Ø 删除残存在转发表中不再有效的路由。
Ø 向区域内刷新那些源于自己的LSA。
Ø 刷新掉Grace-LSA。
监视网络变化,如果没有变化,就保持宣告与GR Restarter的邻接状态不变。
Ø 目前与GR Restarter设备在进入帮助状态的接口上是FULL的状态。
Ø 网络拓扑没有变化。检查的方法是查看与GR Restarter设备连接的重传列表(半小时一次的刷新周期除外)。如果有网络变化,那么拒绝进入帮助模式。对于LSA变化的定义如下
l Options字段发生了改变。
l LSA的age被设为了最大
l LSA头部的长度字段发生了变化
l 除头部以外的内容发生了变化(除去头部目的是为了不考虑校验和及序列号)
Ø GR周期没有过(根据Grace-LSA的age字段来判断)。
Ø 本地策略允许成为GR Helper。
Ø 本身不在GR过程中。
Ø 例外是,如果已经是某个GR Restarter设备的帮助模式,那么收到新的Grace-LSA必须接受并且因此更新GR周期。
GR Helper可能与GR Restarter设备有多个邻接关系,如果在其中的一个连接上拒绝进入帮助模式,会导致问题。因为不进入帮助模式将宣告一个邻接结束。而这样会导致LSA的更新,并被理解为网络拓扑发生了变化。
Ø Grace-LSA被刷新了(说明GR Restarter设备已经完成GR)。
Ø GR周期过期。
Ø LSDB显示网络发生了变化,也就是LSA变化了。并且要满足这样的条件,如果FULL的关系还存在,那么该LSA是会被泛洪给GR设备的。也就是说这个网络拓扑的变化会影响到GR Restarter对网络设备拓扑的理解。举个例子(图3):如果Y是一个ABR,并且是GR Helper的角色。X属于一个STUB区域,是GR Restarter的角色。如果Y收到一个新的5类LSA,那么并不会终止GR过程,因为这个LSA任何时候都不会泛洪给X。
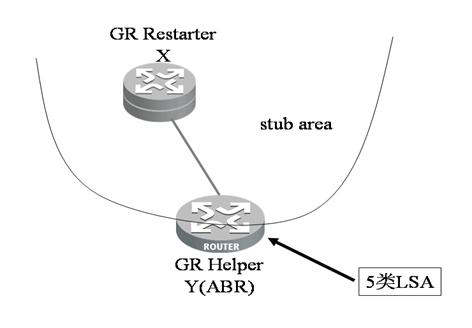
图4 GR Restarter对网络拓扑变化的理解
Ø 重新计算DR。
Ø 重新泛洪1类LSA。
Ø 如果是DR,重新泛洪2类LSA。
Ø 如果连接了VLINK,在传输区域产生1类LSA。
通过前面的介绍,我们发现,一个GR过程似乎是有计划进行的,那么很多时候是因为主控板出现意外故障导致了主备切换,这时候的GR过程会有所不同。
GR技术的起源是用于有计划的重起,对于无计划的重起而言,要考虑到是否转发表能有效的得到保护。另一方面非计划的重起,并没有进行应做的准备,那么在控制软件可用时需要立刻发出一个Grace-LSA并要遵守下面的原则。
Ø Grace-LSA必须在发送任何HELLO之前产生并发送出去。在广播网络中,这个LSA必须向所有路由器的组播地址发送,因为重起的设备并不知道它之前的DR状态。
Ø Grace-LSA是封装在LSU报文中并送到所有的接口,不管是否存在邻接关系或者以前的邻接关系是如何的。
Ø 为了提高Grace-LSA被交付的概率,具体实现中可以进行多次的发送。
Ø 在Grace-LSA中重起原因中要设置为0(不可知)或者3(切换到备份控制器)。这样邻居就可以决定是否他们需要帮助路由器完成这个意外的重起。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS age=0 | Options | LS type= 9 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Opaque type=3 | Oaque ID = 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Advertising Router |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS sequence number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| LS checksum | length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+- TLVs -+
| ... |
每一个TLV都是4字节对齐的。格式如下
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Type | Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Value... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Length描述了Value有效部分的长度。
TLV含义 | T | L | V | 在GR-LSA中 |
GR周期 | 1 | 4 | 以秒为单位 | 必须包含 |
GR原因 | 2 | 1 | 0 (未知原因) 1 (software restart), 2 (software reload/upgrade) 3 (主备倒换) | 必须包含 |
接口IP地址 | 3 | 4 | 接口的IP地址 | 在广播、NBMA及点到多点网络类型中。 |
一个虚假的Grace-LSA会导致设备进入GR Helper的角色,并孤立起来。
解决的方法是对OSPF的邻居交互做认证。



 新浪微博
新浪微博 腾讯微博
腾讯微博 豆瓣空间
豆瓣空间 搜狐微博
搜狐微博 QQ空间
QQ空间 腾讯朋友
腾讯朋友 网易微博
网易微博 百度搜藏
百度搜藏 告诉聊友
告诉聊友